一、hadoop HA介绍
大纲:
NameNode高可用整体架构
NameNode的主备切换
NameNode的共享存储
1.1 NameNode高可用整体架构
架构如下图所示:
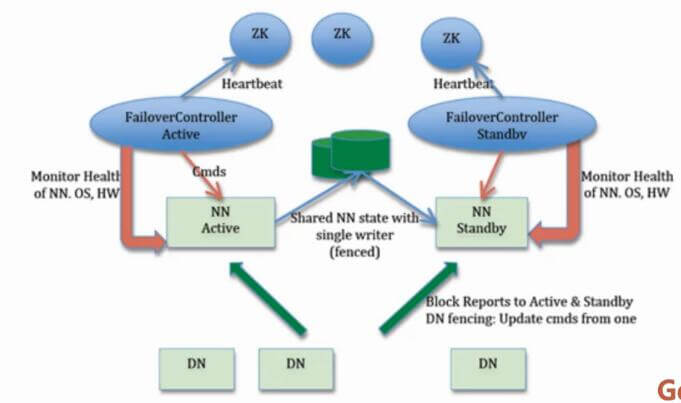
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
组件:
- Active NameNode
- Standby NameNode
- ZKFailoverController
- Zookeeper集群
- 共享存储系统
- DataNode
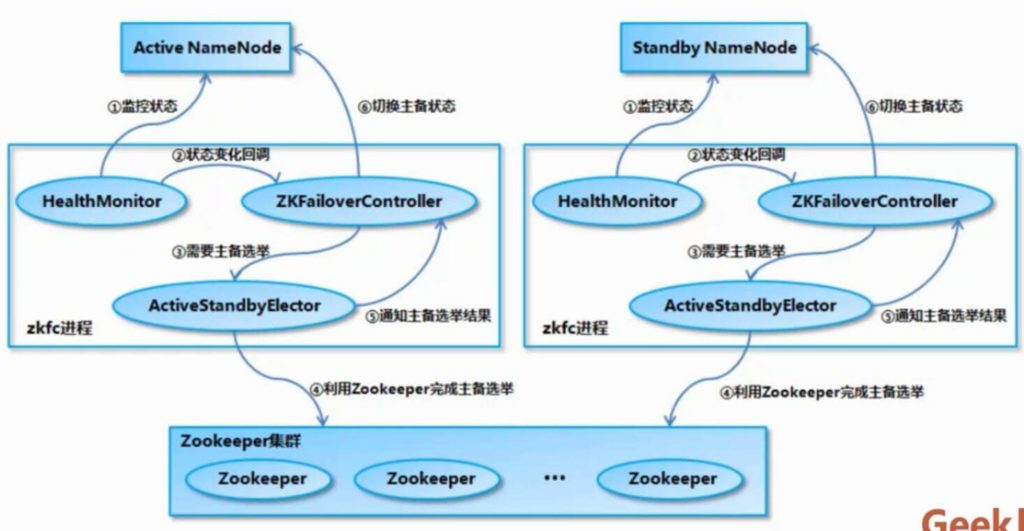
1.2 NameNode主备切换
流程图:
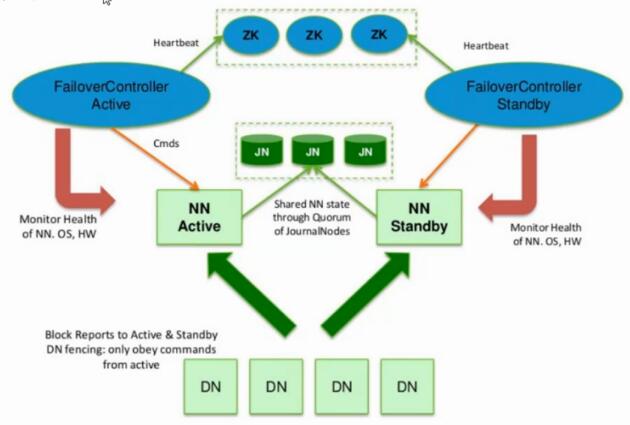
1.3 NameNode的共享储存
架构图:
NameNode 初始化启动,进入 Standby 状态
在 NameNode 以 HA 模式启动的时候,NameNode 会认为自己处于 Standby 模式,在 NameNode 的构造函数中会加载 FSImage 文件和 EditLog Segment 文件来恢复自己的内存文件系统镜像。在加载 EditLog Segment 的时候,调用 FSEditLog 类的 initSharedJournalsForRead 方法来创建只包含了在 JournalNode 集群上的共享目录的 JournalSet,也就是说,这个时候只会从 JournalNode 集群之中加载 EditLog,而不会加载本地磁盘上的 EditLog。另外值得注意的是,加载的 EditLog Segment 只是处于 finalized 状态的 EditLog Segment,而处于 in-progress 状态的 Segment 需要后续在切换为 Active 状态的时候,进行一次数据恢复过程,将 in-progress 状态的 Segment 转换为 finalized 状态的 Segment 之后再进行读取。
加载完 FSImage 文件和共享目录上的 EditLog Segment 文件之后,NameNode 会启动 EditLogTailer 线程和 StandbyCheckpointer 线程,正式进入 Standby 模式。如前所述,EditLogTailer 线程的作用是定时从 JournalNode 集群上同步 EditLog。而 StandbyCheckpointer 线程的作用其实是为了替代 Hadoop 1.x 版本之中的 Secondary NameNode 的功能,StandbyCheckpointer 线程会在 Standby NameNode 节点上定期进行 Checkpoint,将 Checkpoint 之后的 FSImage 文件上传到 Active NameNode 节点。
NameNode 从 Standby 状态切换为 Active 状态
当 NameNode 从 Standby 状态切换为 Active 状态的时候,首先需要做的就是停止它在 Standby 状态的时候启动的线程和相关的服务,包括上面提到的 EditLogTailer 线程和 StandbyCheckpointer 线程,然后关闭用于读取 JournalNode 集群的共享目录上的 EditLog 的 JournalSet,接下来会调用 FSEditLog 的 initJournalSetForWrite 方法重新打开 JournalSet。不同的是,这个 JournalSet 内部同时包含了本地磁盘目录和 JournalNode 集群上的共享目录。这些工作完成之后,就开始执行“基于 QJM 的共享存储系统的数据恢复机制分析”一节所描述的流程,调用 FSEditLog 类的 recoverUnclosedStreams 方法让 JournalNode 集群中各个节点上的 EditLog 达成一致。然后调用 EditLogTailer 类的 catchupDuringFailover 方法从 JournalNode 集群上补齐落后的 EditLog。最后打开一个新的 EditLog Segment 用于新写入数据,同时启动 Active NameNode 所需要的线程和服务。
NameNode 从 Active 状态切换为 Standby 状态
当 NameNode 从 Active 状态切换为 Standby 状态的时候,首先需要做的就是停止它在 Active 状态的时候启动的线程和服务,然后关闭用于读取本地磁盘目录和 JournalNode 集群上的共享目录的 EditLog 的 JournalSet。接下来会调用 FSEditLog 的 initSharedJournalsForRead 方法重新打开用于读取 JournalNode 集群上的共享目录的 JournalSet。这些工作完成之后,就会启动 EditLogTailer 线程和 StandbyCheckpointer 线程,EditLogTailer 线程会定时从 JournalNode 集群上同步 Edit Log。
二、搭建hadoop2 HA
大纲:
实验环境讲解
演示Hadoop HA步骤并讲解
2.1 实验环境讲解
架构:
namenode1
namenode2
datanode
Hadoop 2.x 的两个NameNode一般会配置在两台独立的机器上,Active NameNode会响应集群客户端,而Standby NameNode只是作为Active NameNode的备份,保证在Active NameNode出现问题时能够快速的替代它。
Standby NameNode通过JournalNodes的通信来与Active NameNode保持同步。
Active NameNode和Standby NameNode在哪个节点上,是由zookeeper通过主备选举机制来确定的。
HDFS HA配置:
NameNode:对应配置相同的两台物理机,分别运行Active NameNode和Standby NameNode。
JournalNode:JournalNode不会耗费太多的资源,可以和其它进程部署在一起,如NameNode、Datanode、ResourceManager等,需要至少3个且为基数,这样可以允许(N-1)/2个JNS进程失败。
DataNode:根据数据量的大小和处理数据所需资源进行配置,一般实际应用中数量较多,且分布在较多的机器上。
规则:
| 主机名 | IP | 安装软件 | JPS启动进程 |
| hadoop-namenode1 | 192.168.152.153 | JDK/Zookeeper/Hadoop | namenode/zkfc/journalnode/resourcemanager/QuoqumPeerMain |
| hadoop-namenode2 | 192.168.152.155 | JDK/Zookeeper/Hadoop | namenode/zkfc/journalnode/resourcemanager/QuoqumPeerMain |
| hadoop-datanode1 | 192.168.152.154 | JDK/Zookeeper/Hadoop | datanode//journalnode/nodemanager/QuoqumPeerMain |
配置:
CentOS-7-x86_64-Minimal-1511.iso
jdk-8u101-linux-x64.tar.gz
zookeeper-3.4.8.tar.gz
hadoop-2.6.0.tar.gz
2.2 演示Hadoop HA步骤并讲解
2.2.1 安装centos 7
2.2.1.1 安装虚拟机和Linux系统
安装最小化centos,比较简单,也不做详细描述。我没有设置账户,所以开机后的账户为root账户,密码自己设置。
2.2.1.2 配置、连接网络
centos安装后需要手动联网(如需设置静态ip可自行查阅相关资料):
开机后登陆root:
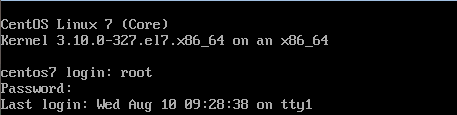
修改文件进行联网:
cd /etc/sysconfig/network-scripts/
vi ifcfg-eno16777736
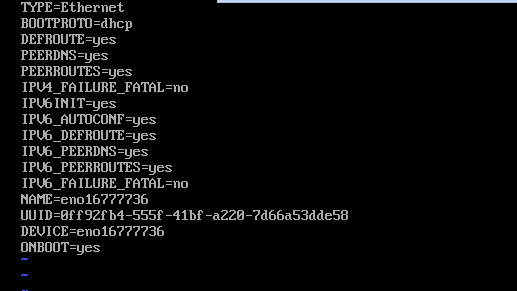
且分别加入主机名和IP地址:
IPADDR=192.168.152.153 //其它节点将最后一个数字加1即可,按照集群规划的IP进行设置
重启网络服务
service network restart
![]()
修改主机名:
hostnamectl set-hostname 主机名
// 此处的主机名分别为hadoop-namenode1,hadoop-namenode2,hadoop-datanode1
查看主机名
hostnamectl status
2.2.1.3 设置IP地址和主机名映射
su root
vim /etc/hosts
192.168.152.155 hadoop-namenode1
192.168.152.153 hadoop-namenode2
192.168.152.154 hadoop-datanode1以下步骤在centos7最小化安装过程中可以不进行操作,因为centos7最小化安装时没有安装防火墙:
关闭防火墙和Selinux
systemctl stop firewalld.service //关闭防火墙
systemctl disable firewalld.service //禁止Firewalls开机启动(此版本的centos没有安装防火墙)
vim /etc/selinux/config
SELINUX=disabled //开机关闭Selinux
重启,查看Selinux状态
gentenforce
2.2.2 Hadoop安装前的准备
2.2.2.1 创建组和用户并添加权限
groupadd hadoop //创建组hadoop
useradd -g hadoop hadoop //创建组hadoop下的用户hadoop
passwd hadoop //修改用户hadoop的密码
yum install vim //安装vim
vim /etc/sudoers //修改配置文件sudoers给hadoop用户添加sudo权限,添加以下内容:
hadoop ALL=(ALL) ALL

2.2.2.2 配置SSH免密码登录
在namenode1节点上生成SSH密钥对
su hadoop
$ ssh-keygen -t rsa
将公钥复制到集群所有节点机器上
$ ssh-copy-id hadoop-nam/code>
$ ssh-copy-id hadoop-namenode2
$ ssh-copy-id hadoop-datanode1
通过ssh登录各节点测试是否免密码登录成功
ssh 节点名
注:确保通过ssh可以免密码登录其它的所有节点
2.2.2.3 在Windows下安装xshell上传安装文件到虚拟机
此步骤不属于hadoop安装,但可以简便安装和使用的操作
在Linux系统中通过以下指令查看ip
ip addr //此处与centos7之前的指令ifconfig不同,是版本升级后的改动
在xshell中通过“文件→打开→新建”来创建连接,名称随意填写,主机填写ip地址,用户和密码处填写账户root和密码(根据自己的设定填写):
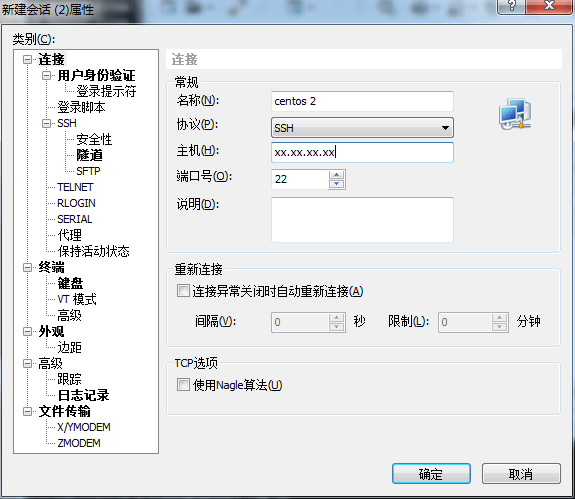
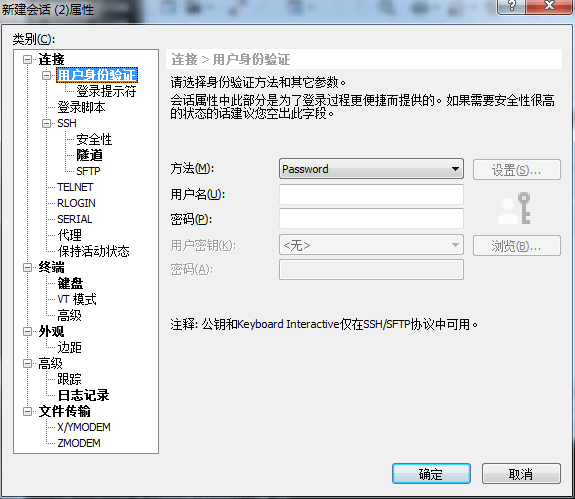
点击“确定→连接→接受”即可连接到Linux系统,但是上传文件之前需要在Linux系统中安装相关应用:
yum install lrzsz //此步骤可能需要在root用户下进行操作,切换回root就行了

在xshell上通过以下指令上传Hadoop、Zookeeper和JDK安装文件:
su hadoop
rz
此外,以下步骤可通过xshell操作Linux虚拟系统。
2.2.3 Hadoop安装、配置
2.2.3.1 安装JDK
卸载自带的openjdk(centos7没有自带的openjdk,所以直接安装jdk即可)
创建安装路径:
mkdir apache
tar -xvf jdk-8u101-linux-x64.tar.gz /home/hadoop/apache/
配置环境变量:
vim ~/.bash_profile
添加以下内容:
export JAVA_HOME=/home/hadoop/apache/jdk1.8.0_101
export PATH=$PATH:$JAVA_HOME/bin
保存,通过以下指令使环境变量生效:
source ~/.bash_profile
测试JDK是否安装成功:
java -version



2.2.3.2 安装zookeeper集群
解压缩zookeeper安装包
tar -xvf zookeeper3.4.8.tar.gz /home/hadoop/apache/
删除安装包:
rm zookeeper3.4.8.tar.gz
配置hadoop用户权限:
chown -R hadoop:hadoop zookeeper-3.4.8
修改zookeeper的配置文件:
cd apache/zookeeper-3.4.8/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
设置如下:
tickTime=2000 //客户端心跳时间(毫秒)
initLimit=10 //循序心跳间隔的最大时间
syncLimit=5 //同步时限
dataDir=/home/hadoop/apache/zookeeper3.4.8/data //数据存储目录
dataLogDir=/home/hadoop/apache/zookeeper3.4.8/data/log //数据日志存储目录
clientPort=2181 //端口号
maxClientCnxns=2000 //连接zookeeper的最大数量
server.1=hadoop-namenode1:2888:3888 //设置zookeeper的节点
server.2=hadoop-namenode2:2888:3888
server.3=hadoop-datanode1:2888:3888创建zookeeper的数据存储目录和日志存储目录:
cd ..
mkdir -p data/log
修改数据存储文件和日志文件的权限:
chown -R hadoop:hadoop data
cd data
chown -R hadoop:hadoop log
在data目录下创建文件myid,输入内容为1
echo "1" >> data/myid //待工作目录同步到其它两个节点后分别修改内容为2和3
将zookeeper工作目录同步到集群其它节点
scp -r zookeeper-3.4.8 hadoop@hadoop-namenode2:/home/hadoop/apache/
scp -r zookeeper-3.4.8 hadoop@hadoop-datanode1:/home/hadoop/apache/
分别修改myid的值为2和3,并配置所有节点的环境变量。
vim ~/.bash_profile
export ZOOKEEPER_HOME=/home/hadoop/apache/zookeeper-3.4.8
export PATH=$PATH:$ZOOKEEPER_HOME/bin到这里zookeeper的集群就已经搭建好了,下面进行启动:
zkServer.sh start
查看进程:
jps
2.2.3.3 Hadoop的安装和配置
在namenode1节点下解压缩安装文件
tar -xvf hadoop-2.6.0.tar.gz /home/hadoop/apache/
删除安装文件
rm hadoop2.6.0.tar.gz
设置用户权限
cd apache
chown -R hadoop:hadoop hadoop-2.6.0/
配置文件
cd hadoop-2.6.0/etc/hadoop/
vim hadoop-env.sh
按如下内容进行配置(具体配置情况需按照生产环境和条件进行配置):
export JAVA_HOME=/home/hadoop/apache/jdk1.8.0_101 //设置jdk路径
export HADOOP_HEAPSIZE=1024 //设置Hadoop位置文本的大小
export HADOOP_NAMENODE_OPTS="-Xmx1024m-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" //设置Namenode内存大小,此处根据实际情况设定其大小
export HADOOP_DATANODE_OPTS="-Xmx1024 -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS //设置Datanode内存大小
export HADOOP_PORTMAP_OPTS="-Xmx1024m $HADOOP_PORTMAP_OPTS" //修改至1024m
export HADOOP_PID_DIR=/home/hadoop/apache/hadoop-2.6.0/pids //设置PID到本地
export HADOOP_LOG_DIR=/home/hadoop/apache/hadoop-2.6.0/data/logs //设置日志的输出路径保存后,创建刚才设定的目录:
cd /home/hadoop/apache/hadoop-2.6.0
mkdir pids
mkdir -p data/logs
配置core-site.xml:
cd etc/hadoop
vim core-site.xml
<configuration>
<!-- 指定hdfs的nameservices名称为mycluster,与hdfs-site.xml的HA配
置相同 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 设置zookeeper集群的配置和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-namenode1:2181,hadoop-namenode2:2181,hadoop-datanode1:2181</value>
</property>
<!-- 指定缓存文件存储的路径和大小(可以设置的大一些,单位:字节)
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/apache/hadoop-2.6.0/data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 配置hdfs文件被永久删除前保留的时间(单位:分钟),默认值为0,表明垃圾回收站功能关闭 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>配置hdfs-site.xml:
vim hdfs-site.xml
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/apache/hadoop-2.6.0/data/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/apache/hadoop-2.6.0/data/datanode</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //////////////以下为HDFS HA的配置////////////// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定mycluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop-namenode1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop-namenode2:8020</value>
</property>
<!-- 配置nn1,nn2的http通信端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop-namenode1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop-namenode2:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-namenode1:8485;hadoop-namenode2:8485;hadoop-datanode1:8485/mycluster</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/apache/hadoop-2.6.0/data/journal</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
配置mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<!-- 指定MapReduce计算框架使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定jobhistory server的rpc地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-namenode1:10020</value>
</property>
<!-- 指定jobhistory server的http地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-namenode1:19888</value>
</property>
<!-- 开启uber模式(针对小作业的优化) -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置启动uber模式的最大map数 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>3</value>
</property>
<!-- 配置启动uber模式的最大reduce数 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
</configuration>配置yarn-site.xml文件:
vim yarn-site.xml
<configuration>
<!-- NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置Web Application Proxy安全代理(防止yarn被攻击) -->
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop-namenode2:8888</value>
</property>
<!-- 开启日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志删除时间为7天,-1为禁用,单位为秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/logs</value>
</property>
<!-- 配置nodemanager可用的资源内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<!-- 配置nodemanager可用的资源CPU -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<!-- //////////////以下为YARN HA的配置////////////// -->
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-namenode1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-namenode2</value>
</property>
<!-- 配置YARN的http端口 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop-namenode1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop-namenode2:8088</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-datanode1:2181</value>
</property>
<!-- 配置zookeeper的存储位置 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<!-- 开启yarn resourcemanager restart -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置resourcemanager的状态存储到zookeeper中 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
</configuration>配置slave文件:
vim slaves
hadoop-datanode1创建配置文件中涉及到的目录:
cd ../..
mkdir -p data/tmp
mkdir -p data/journal
mkdir -p data/namenode
mkdir -p data/datanode
将hadoop工作目录同步到集群其它节点
scp -r hadoop-2.6.0 hadoop@hadoop-namenode2:/home/hadoop/apache/
scp -r hadoop-2.6.0 hadoop@hadoop-datanode1:/home/hadoop/apache/
在所有节点上配置环境变量:
vim ~/.bash_profile
export HADOOP_HOME=/home/hadoop/apache/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin使修改后的环境变量生效:
source ~/.bash_profile
Hadoop集群初始化
在所有节点上启动zookeeper集群:
zkServer.sh start
在hadoop-namenode1上格式化zkfc:
hdfs zkfc -formatZK
启动journalnode(在namenode1,namenode2和datanode1上):
hadoop-daemon.sh start journalnode
格式化HDFS(在hadoop-namenode1上):
hadoop namenode -format
将格式化后namenode1节点hadoop工作目录中的元数据目录复制到namenode2节点
scp-r /home/hadoop/apache/hadoop-2.6.0/data/namenode/* hadoop@hadoop-namenode2:/home/hadoop/apache/hadoop-2.6.0/data/namenode/
启动Hadoop集群
在hadoop-namenode1上启动dfs:
start-dfs.sh
start-dfs.sh命令会开启以下进程:
namenode (namenode1/namenode2)
journalnode (namenode1/namenode2/datanode1)
DFSZKFailoverController (namenode1/namenode2)
datanode (datanode1)
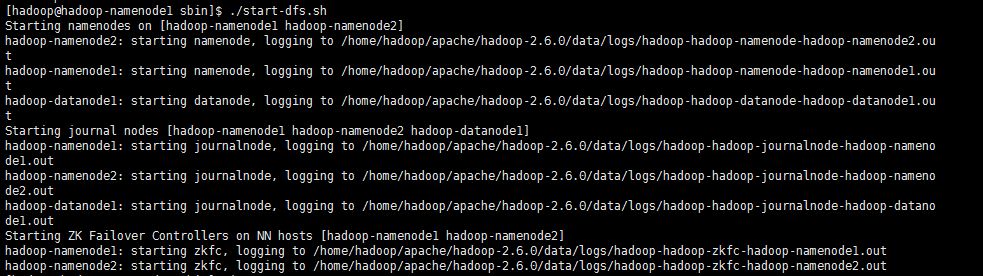
查看进程(所有节点):
jps


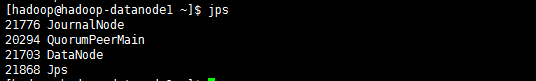
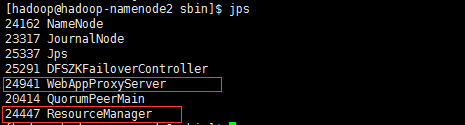
启动YARN(在namenode2上操作)
start-yarn.sh
注:此命令在namenode2节点上启动了ResourceManager,在datanode1上启动了NodeManager

启动YARN上用于容灾的另一个ResourceManager(在namenode1上操作)
yarn-daemon.sh start resourcemanager
启动YARN的安全代理(在namenode2上操作)
yarn-daemon.sh start proxyserver
注:proxyserver充当防火墙的角色,提高访问集群的安全性
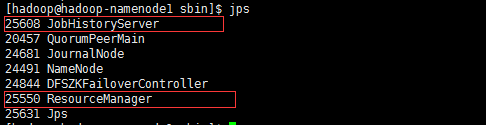
启动YARN的历史任务服务(namenode1上)
mr-jobhistory-daemon.sh start historyserver
至此,Hadoop集群安装配置完成。
2.2.3.4 查看Web UI
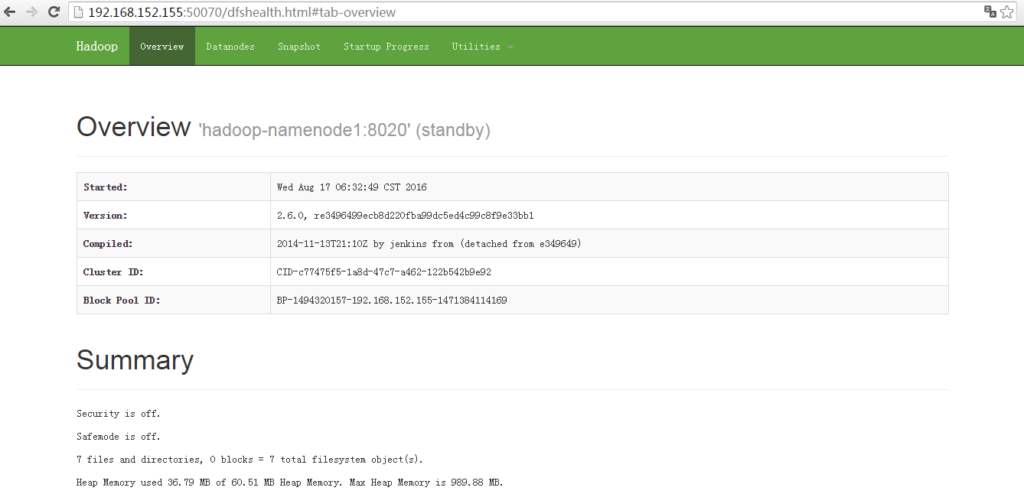
http://hadoop-namenode1:50070,可看到NameNode为standby状态
(注:active namenode在哪一个节点上,是由zookeeper通过主备选举产生的,重复多次启动可能会引起zookeeper的选举结果不同,建议不要重复多次启动。实际应用中服务器一般不会多次启动,所以在实际应用中无较大影响):
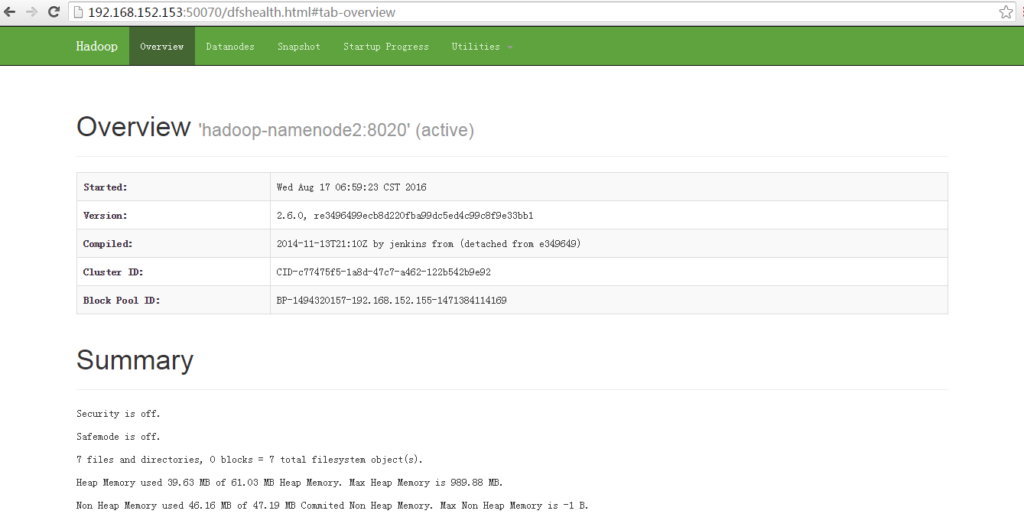
http://hadoop-namenode2:50070,可看到NameNode为active状态
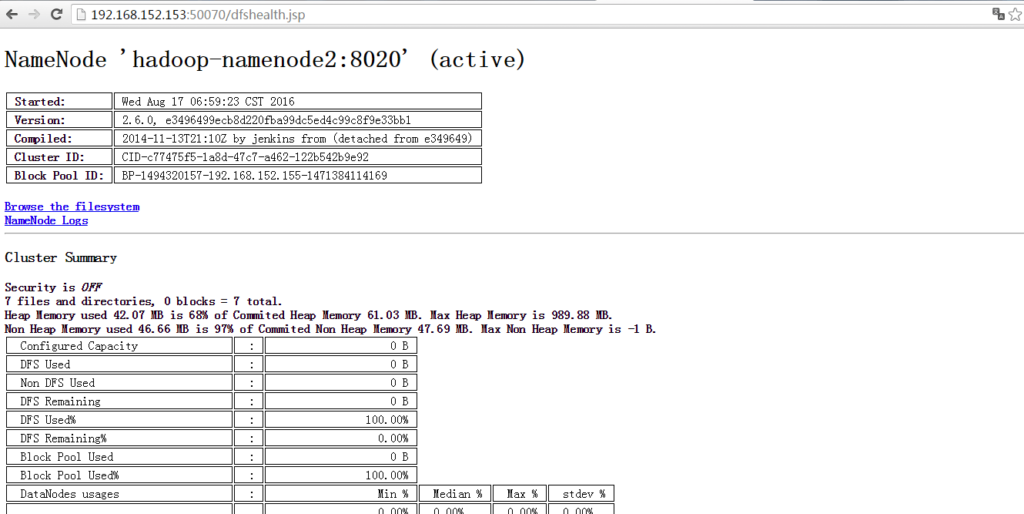
HDFS的隐藏UI页面http://hadoop-namenode1:50070/dfshealth.jsp比较好用,可以方便的查看HDFS文件信息:
(注:此处打开Browse the filesystem时可能会连接不上,则需要在Windows系统上配置Linux虚拟机的主机名和IP,具体步骤:
复制Linux虚拟机的host文件内的主机名和IP:
su
more /etc/hosts/ //复制该文件内的主机名和IP信息
写入Windows的hosts文件内:
C:\Windows\System32\drivers\etc
通过记事本打开hosts文件并写入复制的内容,保存)
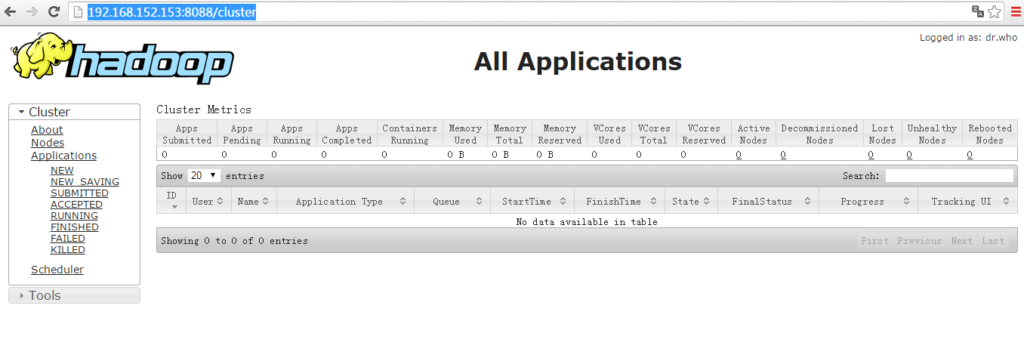
http://hadoop-namenode2:8088,可看到ResourceManager为active状态
http://hadoop-namenode1:8088,可看到ResourceManager为standby状态,它会自动跳转到http://hadoop-namenode2:8088:

http://hadoop-namenode1:19888,可查看历史任务信息: