大纲:
实验环境讲解
演示搭建HBase步骤并讲解
一 实验环境讲解
架构
namenode1(master1)
namenode2(master2)
datanode(regionserver)
使用NameNode1、NameNode2和DataNode1 三个服务器来模拟集群,NameNode1上搭建Hbase和Hmaster,NameNode2搭建Hmaster,与NameNode1互为主备,DataNode1上搭建regionserver,Hbase通过zookeeper来保存活跃的master节点信息,保证活跃的master节点出现问题时,备用master取代主master。
| 主机名 | IP | 安装软件 | JPS启动进程 |
| hadoop-namenode1 | 192.168.152.153 | JDK/Zookeeper/Hadoop/HBase | namenode/zkfc/journalnode/resourcemanager/QuoqumPeerMain/Hmaster |
| hadoop-namenode2 | 192.168.152.155 | JDK/Zookeeper/Hadoop/HBase | namenode/zkfc/journalnode/resourcemanager/QuoqumPeerMain/Hmaster |
| hadoop-datanode1 | 192.168.152.154 | JDK/Zookeeper/Hadoop/HBase | datanode/journalnode/nodemanager/QuoqumPeerMain/Hregionserver |
二 演示搭建HBase步骤并讲解
2.1 准备阶段
2.1.1 查看、修改Linux系统的最大文件打开数和最大进程数
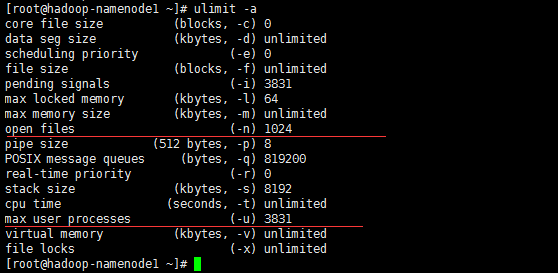
ulimit –a //测试环境一般不用修改,但是商业应用时一般需要修改
su
vim /etc/security/limits.conf
root soft nproc 50000 root hard nproc 50000 root soft nofile 25535 root hard nofile 25535 hadoop soft nproc 50000 hadoop hard nproc 50000 hadoop soft nofile 25535 hadoop hard nofile 25535
2.1.2 调整Linux内核参数
vim /etc/sysctl.conf
net.ipv4.ip_forward= 0 net.ipv4.conf.default.rp_filter= 1 net.ipv4.conf.default.accept_source_route= 0 kernel.core_users_pid= 1 net.ipv4.tcp_syncookies= 1 net.bridge.bridge-nf-call-ip6tables= 0 net.bridge.bridge-nf-call-iptables= 0 net.bridge.bridge-nf-call-arptables= 0 kernel.mggmnb= 65536 kernel.mggmax= 65536 kernel.shmmax= 68719476736 kernel.shmall= 268435456 net.ipv4.tcp_max_syn_backlog= 65000 net.core.netdev_max_backlog= 32768 net.core.somaxconn= 32768 fs.file-max= 65000 net.core.wmem_default= 8388608 net.core.rmem_default= 8388608 net.core.rmem_max= 16777216 net.core.wmem_max= 16777216 net.ipv4.tcp_timestamps= 1 net.ipv4.tcp_synack_retries= 2 net.ipv4.tcp_syn_retries= 2 net.ipv4.tcp_mem= 94500000 915000000 927000000 net.ipv4.tcp_max_orphans= 3276800 net.ipv4.tcp_tw_reuse= 1 net.ipv4.tcp_tw_recycle= 1 net.ipv4.tcp_keepalive_time= 1200 net.ipv4.tcp_syncookies= 1 net.ipv4.tcp_fin_timeout= 10 net.ipv4.tcp_keepalive_intvl= 15 net.ipv4.tcp_keepalive_probes= 3 net.ipv4.ip_local_port_range= 1024 65535 net.ipv4.conf.eml.send_redirects= 0 net.ipv4.conf.lo.send_redirects= 0 net.ipv4.conf.default.send_redirects= 0 net.ipv4.conf.all.send_redirects= 0 net.ipv4.icmp_echo_ignore_broadcasts= 1 net.ipv4.conf.eml.accept_source_route= 0 net.ipv4.conf.lo.accept_source_route= 0 net.ipv4.conf.default.accept_source_route= 0 net.ipv4.conf.all.accept_source_route= 0 net.ipv4.icmp_ignore_bogus_error_responses= 1 kernel.core_pattern= /tmp/core vm.overcommit_memory= 1
保存修改后sysctl -p。
2.1.3 配置时间同步
如果集群节点时间不同步,可能会出现节点宕机或其它异常,生产环境中一般通过配置NTP服务器实现集群时间同步,需要确保各节点的时间差在10s以内,有条件最好隔一段时间同步一次。本集群在节点hadoop-namenode1中设置ntp服务器,具体方法如下:
切换至root用户
su root
查看、安装ntp
pm -qa | grep ntp
yum install -y ntp
配置时间服务器
vim /etc/ntp.conf
禁止所有机器连接ntp服务器
restrict default ignore
允许局域网内的所有机器连接ntp服务器
restrict 192.168.152.0 mask 255.255.255.0 nomodify notrap
使用本机作为时间服务器
server 127.127.1.0
启动ntp服务器
service ntpd start
设置ntp服务器开机自动启动
chkconfig ntpd on
集群其它节点通过执行crontab定时任务,每天在指定时间向ntp服务器进行时间同步,方法如下:
切换root用户
su root
执行定时任务,每天00:00向服务器同步时间,并写入日志
crontab -e
0 0 * * * /usr/sbin/ntpdate hadoop-namenode1>> /home/hadoop/ntpd.log
// 查看任务
crontab -l
2.2 Hbase的安装、配置
2.2.1 下载、安装Hbase
此处版本为:
hbase-1.2.2-bin.tar.gz
解压安装Hbase:
tar zxvf hbase-1.2.2-bin.tar.gz
删除安装文件:
rm hbase-1.2.2-bin.tar.gz
2.2.2 配置环境
cd /home/hadoop/apache/hbase-1.2.2/conf
vim hbase-env.sh
export JAVA_HOME=/home/hadoop/apache/jdk1.8.0_101 //设置jdk的路径
export HBASE_HEAPSIZE=1024 //设置hbase的堆(内存)的大小
export HBASE_MASTER_OPTS=”-Xmx512m” //设置hmaster的内存,企业级一般为4-8G
export HBASE_REGIONSERVER_OPTS=”-Xmx1024m” //设置regionserver的大小
export HBASE_LOG_DIR=${HBASE_HOME}/logs //设置hbase日志路径
export HBASE_PID_DIR=/home/hadoop/apache/hbase-1.2.2/pids
export HBASE_MANAGES_ZK=false //选用独立的zookeeper集群vim hbase-site.xml
<!-- 关闭分布式日志切割,如果采用true会采用regionserver去对日志进行切割,但会产生大量的IO内存的消耗,建议填写false --> <property> <name>hbase.master.distributed.log.splitting</name> <value>false</value> </property> <!-- 设置hdfs的根路径,HRegionServers共享目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <!-- 开启分布式模式,false为单机模式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 设置HMaster的rpc端口 --> <property> <name>hbase.master.port</name> <value>60000</value> </property> <!-- 指定ZooKeeper集群位置列表 --> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop-namenode1,hadoop-namenode2,hadoop-datanode1</value> </property> <!-- 指定Zookeeper数据目录,需要与ZooKeeper集群上配置相一致 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/apache/zookeeper-3.4.8/data</value> </property> <!-- hbase客户端rpc扫描一次调用的行数,提高扫描速度,但是会占用一定内存 --> <property> <name>hbase.client.scanner.caching</name> <value>2000</value> </property> <!-- HRegion分裂前最大的文件大小(默认10G) --> <property> <name>hbase.hregion.max.filesize</name> <value>10737418240</value> </property> <!-- 某个HRegionServer中最大的region数量,一般设置在2000左右 --> <property> <name>hbase.regionserver.reginoSplitLimit</name> <value>2000</value> </property> <!-- StoreFile的开始合并的数量,即个数超过这个数就开始合并,值越大合并的时间越长,默认值为3 --> <property> <name>hbase.hstore.compactionThreshold</name> <value>6</value> </property> <!-- 当一个region的storefile个数多于这个值的的时候,它会执行一个合并操作(block写入,等待compact),且会阻塞更新操作。默认为7,一般可以设置为15-20左右,设置太小会影响系统的吞吐率 --> <property> <name>hbase.hstore.blockingStoreFiles</name> <value>14</value> </property> <!-- 超过memstore大小的倍数达到该值则block所有写入请求,阻塞更新操作,进行自我保护 --> <property> <name>hbase.hregion.memstore.block.multiplier</name> <value>20</value> </property> <!-- server端后排线程的sleep间隔,默认为10000,单位:ms --> <property> <name>hbase.server.thread.wakefrequency</name> <value>500</value> </property> <!-- ZooKeeper客户端同时访问的最大并发连接数,zookeeper也要设置,都设置了才能发挥作用,建议设大一点,2000左右,比较重要 --> <property> <name>hbase.zookeeper.property.maxClientCnxns</name> <value>2000</value> </property> <!-- 设置一个regionserver里面menstore占总堆的百分比,达到设定的值以后,会让大的menstore刷写到磁盘,后两个值相加要小于0.8,否则会出现out of memory,根据业务情况进行配置 --> <property> <name>hbase.regionserver.global.memstore.lowerLimit</name> <value>0.3</value> </property> <property> <name>hbase.regionserver.global.memstore.upperLimit</name> <value>0.39</value> </property> <property> <name>hbase.block.cache.size</name> <value>0.4</value> </property> <!-- RegionServer的RPC请求处理IO线程数 --> <property> <name>hbase.reginoserver.handler.count</name> <value>300</value> </property> <!-- 客户端最大重试次数,默认为10 --> <property> <name>hbase.client.retries.number</name> <value>5</value> </property> <!-- 客户端重试前的休眠时间,单位:ms --> <property> <name>hbase.client.pause</name> <value>100</value> </property> <!-- 指定ZooKeeper集群端口 --> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property>
vim regionservers //添加regionserver节点主机名
hadoop-datanode1
复制hdfs-site.xml到conf目录下
cp /home/hadoop/apache/hadoop-2.6.0/etc/hadoop/hdfs-site.xml .
vim backup-masters //添加备用Hmaster节点主机名
hadoop-namenode2
创建hbase的缓存文件目录、日志文件目录和pid文件目录
cd /home/hadoop/apache/hbase-1.2.2/
mkdir tmp
mkdir logs
mkdir pids
2.2.3 同步hbase工作目录到集群其它节点
scp -r /home/hadoop/apache/hbase-1.2.2 hadoop@hadoop-namenode2:/home/hadoop/apache/
scp -r /home/hadoop/apache/hbase-1.2.2 hadoop@hadoop-datanode1:/home/hadoop/apache/
2.2.4 在各节点上修改用户环境变量并使其生效,且授予权限
chown -R hadoop:hadoop hbase-1.2.2
vim ~/.bash_profile
export HBASE_HOME=/home/hadoop/apache/hbase-1.2.2 export PATH=$PATH:$HBASE_HOME/bin
source ~/.bash_profile
2.3 启动集群
2.3.1 在各节点上开启zookeeper集群
zkServer.sh start
2.3.2 在hadoop-namenode1上启动hdfs
start-dfs.sh
2.3.3 在hadoop-namenode2上启动yarn
start-yarn.sh
2.3.4 在hadoop-namenode1上启动ResourceManager
yarn-daemon.sh start resourcemanager
2.3.5 在hadoop-namenode1上启动hbase
start-hbase.sh
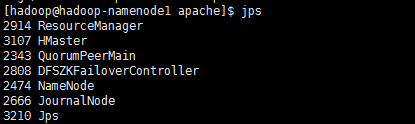
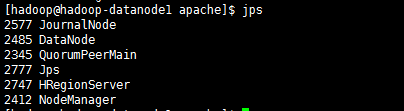
启动后各节点进程如下
hadoop-namenode1:
hadoop-namenode2:

hadoop-datanode1:
2.4 功能测试
2.4.1 Web UI
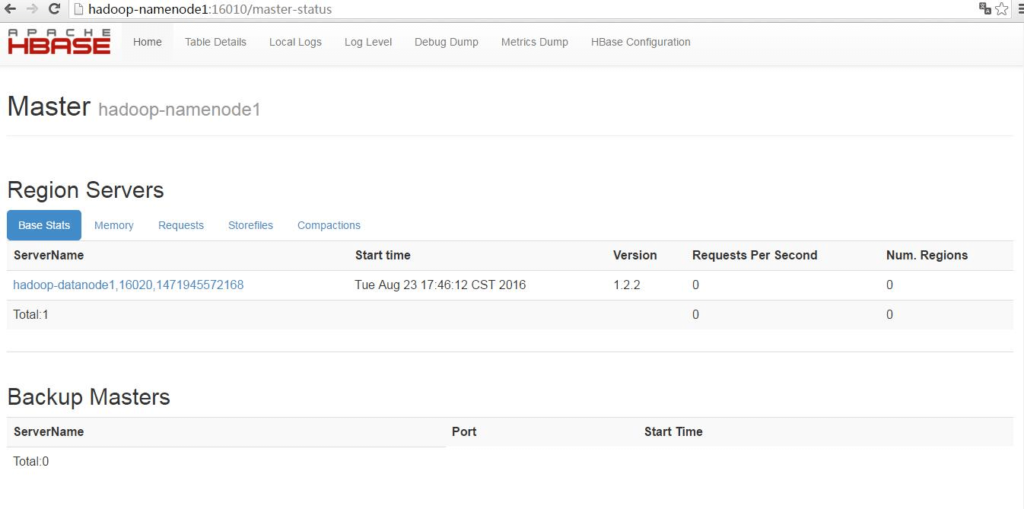
http://hadoop-namenode1:16010,可看到主Master状态
http://hadoop-namenode2:16010,可看到备份Master状态
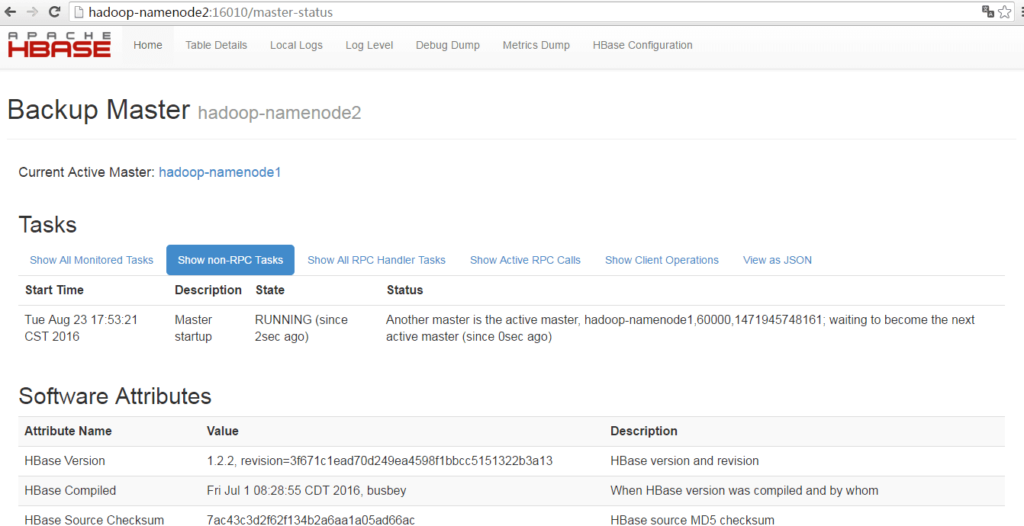
2.4.2 Shell操作
进入Shell
hbase shell
创建表employee,列族data
> create 'employee','data'
往表employee中插入测试数据
> put 'employee','rowkey01','data:id','1001'
> put 'employee','rowkey01','data:name','Henry'
> put 'employee','rowkey01','data:address','Bangalore'
> put 'employee','rowkey02','data:id','1002'
> put 'employee','rowkey02','data:name','Messi'
检索表employee中的所有数据
> scan 'employee'
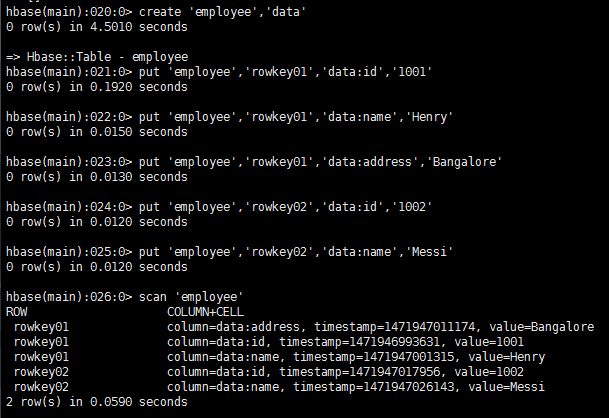
检索表employee中行键为rowkey01的数据
> get 'employee','rowkey01'

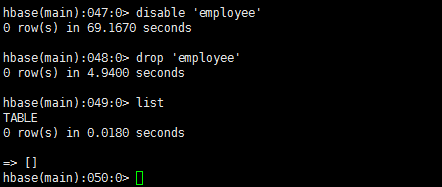
禁用表employee并删除它
> disable 'employee'
> drop 'employee'
2.5 HDFS、HBase动态替换节点
2.5.1 Hadoop、HBase动态增加节点
2.5.1.1 增加Hadoop节点
新节点的IP配置,用户创建,核对时间,修改最大文件读取数、最大用户进程数和内核参数,SSH免密码登录配置等
配置hosts文件,添加主机名和IP地址,且同步到其它节点
修改hadoop的配置文件slaves,添加新节点的主机名
复制JDK和hadoop目录到新的节点(注意新节点的hadoop的data、pids等目录需要清除数据)
新节点hadoop权限的修改
修改新节点的环境变量
在新节点中通过命令Hdfs dfsadmin –setBalancerBandwidth设置字节数、带宽,通过命令start-balancer.sh -threshold 5均衡当前的HDFS块 (threshold是平衡阈值,默认是10%,值越小负载越均衡,但需要更长的时间去执行)
在新节点通过命令hadoop-daemon.sh start datanode和yarn-daemon.sh start nodemanager启动datanode和nodemanager进程
2.5.1.2 增加HBase节点
在HBase的配置文件regionserver中添加新节点的主机名
复制hbase目录到新的节点(注意新节点的data等目录也需要清除数据)
在新节点通过命令hbase-daemon.sh start regionserver启动HRegionServer
在新节点上通过hbase-daemon.sh start regionserver启动regionserver
进入hbase shell,通过命令balance_switch true进行region负载平衡
2.5.2 Hadoop、HBase动态删除节点
2.5.2.1 删除HBase节点
通过‘graceful_stop.sh 节点名’使得需要删除的节点的负载均衡停止使用
在HBase的配置文件regionserver中移除删除节点的主机名
2.5.2.2 删除Hadoop节点
在hadoop的配置文件hdfs-site.xml中添加配置:
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/apache/hadoop-2.6.0/etc/hadoop/exclude</value> </property>
在配置文件exclude中添加需要删除的节点主机名
通过命令hdfsafsadmin -refreshNodes执行节点刷新操作,重新加载配置
通过命令hadoop dfsadmin –report查看集群状态