一、如果是将备份的虚拟机文件重新添加到virtualbox时,需要注意以下几个要点:
1、添加新的虚拟机,选择已有虚拟机文件,导入成功后,进入设置界面,网络选择桥接网络,并记录当前虚拟机的MAC地址。
2、由于重新导入时网卡相当于新的网卡,因此需要删除旧网卡信息。
输入命令:sudo vim /etc/udev/rules.d/70-persistent-net.rules 即网卡的信息,保留最新的网卡信息,其余网卡信息删除。
3、配置当前网卡信息。
输入命令:sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 修改对应的HWADDR属性,即更改为当前虚拟机的MAC地址。
4、上述操作完成,输入reboot命令,重启虚拟机即可。并可通过ifconfig命令验证网络是否已经连接成功。
二、使用eclipse安装Mapreduce插件及执行mapreduce程序
1、安装所对应的eclipse插件,如笔者的hadoop版本为2.6,则需要将对应版本的插件jar包传至eclipse的插件文件夹下,并重启eclipse,附上hadoop-eclipse-plugin-2.6.0.jar的下载地址:链接:http://pan.baidu.com/s/1jIFKVyu 密码:iqhz
2、分别按照下图示意,设置Mapreduce插件。
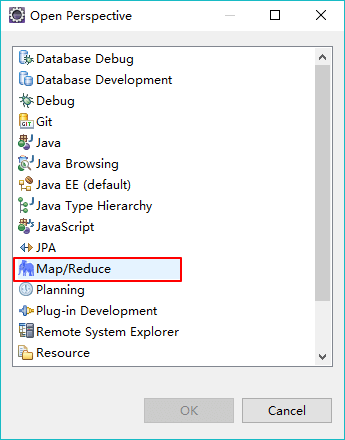
① 重启后默认没有Mapreduce的工作区,因此按下图示意添加:
![]()
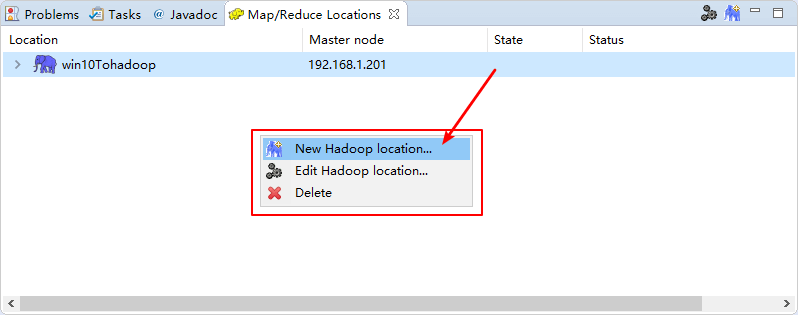
② 添加对应的Hadoop服务器:
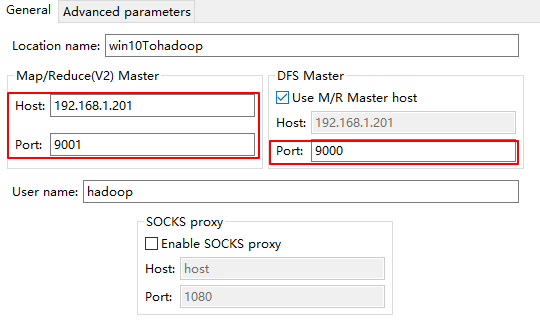
③ 图示为笔者的Hadoop集群信息:
3、第一次新建Mapreduce工程时设置hadoop的本地路径,该hadoop文件包需要时在win上可以执行的,我将2.6版本对应的hadoop文件包下载地址分享出来:链接:http://pan.baidu.com/s/1hrNawN6 密码:edw9
如下图所示进行设置:
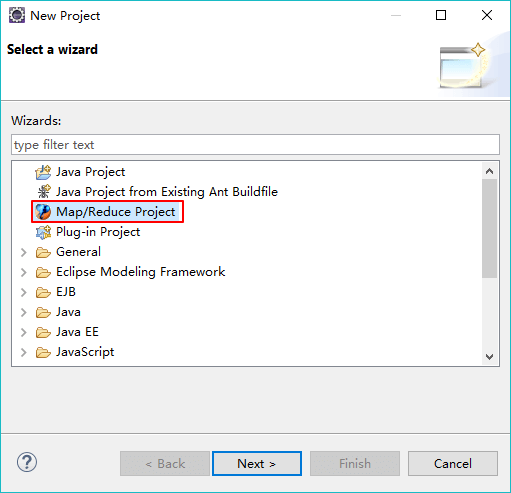
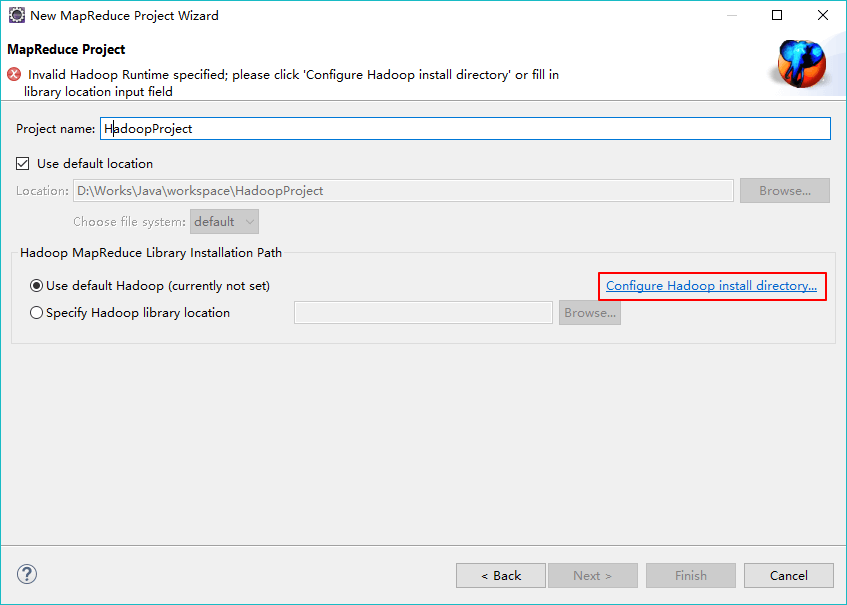
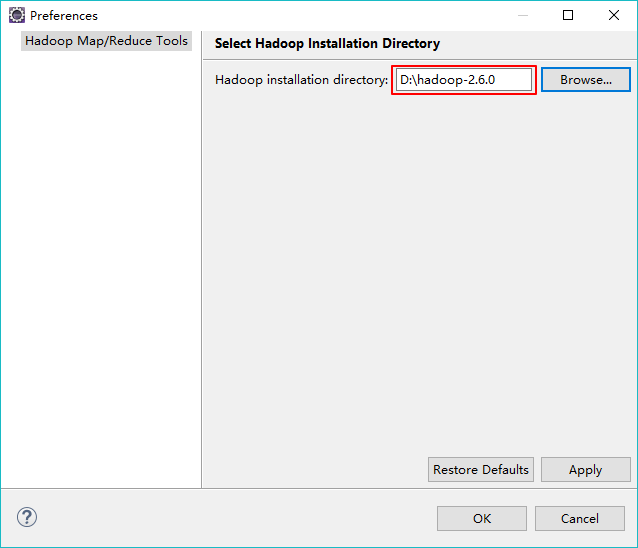
这样新建的工程会将使用到的hadoopjar包自动引用进来。
4、设置hadoop环境变量
因为在windows环境下进行Mapreduce程序的调试,需要设置对应的hadoop环境变量,如下图所示:
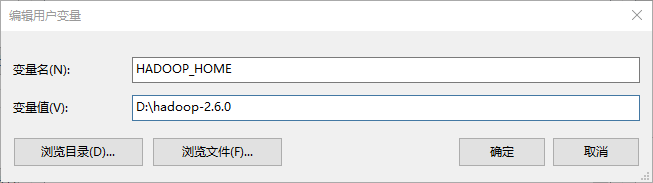
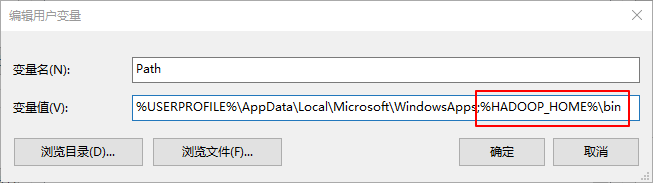
设置完成后,就可进行再windows环境下进行Mapreduce程序的调试。
三、在eclipse下运行mapreduce程序在控制台中显示如图

但是不影响程序产生执行结果,但是就无法看到mapreduce的执行过程,这种情况一般是由于log4j这个日志信息打印模块的配置信息没有给出造成的,可以在项目的src目录下,新建一个文件,命名为“log4j.properties”,填入以下信息:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Define some default values that can be overridden by system properties
hadoop.root.logger=INFO,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}, EventCounter
# Logging Threshold
log4j.threshold=ALL
# Null Appender
log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender
#
# Rolling File Appender - cap space usage at 5gb.
#
hadoop.log.maxfilesize=256MB
hadoop.log.maxbackupindex=20
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file}
log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize}
log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#
# Daily Rolling File Appender
#
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollver at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
# 30-day backup
#log4j.appender.DRFA.MaxBackupIndex=30
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#
# console
# Add "console" to rootlogger above if you want to use this
#
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
#
# TaskLog Appender
#
#Default values
hadoop.tasklog.taskid=null
hadoop.tasklog.iscleanup=false
hadoop.tasklog.noKeepSplits=4
hadoop.tasklog.totalLogFileSize=100
hadoop.tasklog.purgeLogSplits=true
hadoop.tasklog.logsRetainHours=12
log4j.appender.TLA=org.apache.hadoop.mapred.TaskLogAppender
log4j.appender.TLA.taskId=${hadoop.tasklog.taskid}
log4j.appender.TLA.isCleanup=${hadoop.tasklog.iscleanup}
log4j.appender.TLA.totalLogFileSize=${hadoop.tasklog.totalLogFileSize}
log4j.appender.TLA.layout=org.apache.log4j.PatternLayout
log4j.appender.TLA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
#
# HDFS block state change log from block manager
#
# Uncomment the following to suppress normal block state change
# messages from BlockManager in NameNode.
#log4j.logger.BlockStateChange=WARN
#
#Security appender
#
hadoop.security.logger=INFO,NullAppender
hadoop.security.log.maxfilesize=256MB
hadoop.security.log.maxbackupindex=20
log4j.category.SecurityLogger=${hadoop.security.logger}
hadoop.security.log.file=SecurityAuth-${user.name}.audit
log4j.appender.RFAS=org.apache.log4j.RollingFileAppender
log4j.appender.RFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.RFAS.MaxFileSize=${hadoop.security.log.maxfilesize}
log4j.appender.RFAS.MaxBackupIndex=${hadoop.security.log.maxbackupindex}
#
# Daily Rolling Security appender
#
log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd
#
# hadoop configuration logging
#
# Uncomment the following line to turn off configuration deprecation warnings.
# log4j.logger.org.apache.hadoop.conf.Configuration.deprecation=WARN
#
# hdfs audit logging
#
hdfs.audit.logger=INFO,NullAppender
hdfs.audit.log.maxfilesize=256MB
hdfs.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RFAAUDIT.File=${hadoop.log.dir}/hdfs-audit.log
log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize}
log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex}
#
# mapred audit logging
#
mapred.audit.logger=INFO,NullAppender
mapred.audit.log.maxfilesize=256MB
mapred.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.mapred.AuditLogger=${mapred.audit.logger}
log4j.additivity.org.apache.hadoop.mapred.AuditLogger=false
log4j.appender.MRAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.MRAUDIT.File=${hadoop.log.dir}/mapred-audit.log
log4j.appender.MRAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.MRAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.MRAUDIT.MaxFileSize=${mapred.audit.log.maxfilesize}
log4j.appender.MRAUDIT.MaxBackupIndex=${mapred.audit.log.maxbackupindex}
# Custom Logging levels
#log4j.logger.org.apache.hadoop.mapred.JobTracker=DEBUG
#log4j.logger.org.apache.hadoop.mapred.TaskTracker=DEBUG
#log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=DEBUG
# Jets3t library
log4j.logger.org.jets3t.service.impl.rest.httpclient.RestS3Service=ERROR
# AWS SDK & S3A FileSystem
log4j.logger.com.amazonaws=ERROR
log4j.logger.com.amazonaws.http.AmazonHttpClient=ERROR
log4j.logger.org.apache.hadoop.fs.s3a.S3AFileSystem=WARN
#
# Event Counter Appender
# Sends counts of logging messages at different severity levels to Hadoop Metrics.
#
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
#
# Job Summary Appender
#
# Use following logger to send summary to separate file defined by
# hadoop.mapreduce.jobsummary.log.file :
# hadoop.mapreduce.jobsummary.logger=INFO,JSA
#
hadoop.mapreduce.jobsummary.logger=${hadoop.root.logger}
hadoop.mapreduce.jobsummary.log.file=hadoop-mapreduce.jobsummary.log
hadoop.mapreduce.jobsummary.log.maxfilesize=256MB
hadoop.mapreduce.jobsummary.log.maxbackupindex=20
log4j.appender.JSA=org.apache.log4j.RollingFileAppender
log4j.appender.JSA.File=${hadoop.log.dir}/${hadoop.mapreduce.jobsummary.log.file}
log4j.appender.JSA.MaxFileSize=${hadoop.mapreduce.jobsummary.log.maxfilesize}
log4j.appender.JSA.MaxBackupIndex=${hadoop.mapreduce.jobsummary.log.maxbackupindex}
log4j.appender.JSA.layout=org.apache.log4j.PatternLayout
log4j.appender.JSA.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.logger.org.apache.hadoop.mapred.JobInProgress$JobSummary=${hadoop.mapreduce.jobsummary.logger}
log4j.additivity.org.apache.hadoop.mapred.JobInProgress$JobSummary=false
#
# Yarn ResourceManager Application Summary Log
#
# Set the ResourceManager summary log filename
yarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log
# Set the ResourceManager summary log level and appender
yarn.server.resourcemanager.appsummary.logger=${hadoop.root.logger}
#yarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY
# To enable AppSummaryLogging for the RM,
# set yarn.server.resourcemanager.appsummary.logger to
# <LEVEL>,RMSUMMARY in hadoop-env.sh
# Appender for ResourceManager Application Summary Log
# Requires the following properties to be set
# - hadoop.log.dir (Hadoop Log directory)
# - yarn.server.resourcemanager.appsummary.log.file (resource manager app summary log filename)
# - yarn.server.resourcemanager.appsummary.logger (resource manager app summary log level and appender)
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=false
log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender
log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/${yarn.server.resourcemanager.appsummary.log.file}
log4j.appender.RMSUMMARY.MaxFileSize=256MB
log4j.appender.RMSUMMARY.MaxBackupIndex=20
log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout
log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
# HS audit log configs
#mapreduce.hs.audit.logger=INFO,HSAUDIT
#log4j.logger.org.apache.hadoop.mapreduce.v2.hs.HSAuditLogger=${mapreduce.hs.audit.logger}
#log4j.additivity.org.apache.hadoop.mapreduce.v2.hs.HSAuditLogger=false
#log4j.appender.HSAUDIT=org.apache.log4j.DailyRollingFileAppender
#log4j.appender.HSAUDIT.File=${hadoop.log.dir}/hs-audit.log
#log4j.appender.HSAUDIT.layout=org.apache.log4j.PatternLayout
#log4j.appender.HSAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
#log4j.appender.HSAUDIT.DatePattern=.yyyy-MM-dd
# Http Server Request Logs
#log4j.logger.http.requests.namenode=INFO,namenoderequestlog
#log4j.appender.namenoderequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.namenoderequestlog.Filename=${hadoop.log.dir}/jetty-namenode-yyyy_mm_dd.log
#log4j.appender.namenoderequestlog.RetainDays=3
#log4j.logger.http.requests.datanode=INFO,datanoderequestlog
#log4j.appender.datanoderequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.datanoderequestlog.Filename=${hadoop.log.dir}/jetty-datanode-yyyy_mm_dd.log
#log4j.appender.datanoderequestlog.RetainDays=3
#log4j.logger.http.requests.resourcemanager=INFO,resourcemanagerrequestlog
#log4j.appender.resourcemanagerrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.resourcemanagerrequestlog.Filename=${hadoop.log.dir}/jetty-resourcemanager-yyyy_mm_dd.log
#log4j.appender.resourcemanagerrequestlog.RetainDays=3
#log4j.logger.http.requests.jobhistory=INFO,jobhistoryrequestlog
#log4j.appender.jobhistoryrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.jobhistoryrequestlog.Filename=${hadoop.log.dir}/jetty-jobhistory-yyyy_mm_dd.log
#log4j.appender.jobhistoryrequestlog.RetainDays=3
#log4j.logger.http.requests.nodemanager=INFO,nodemanagerrequestlog
#log4j.appender.nodemanagerrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.nodemanagerrequestlog.Filename=${hadoop.log.dir}/jetty-nodemanager-yyyy_mm_dd.log
#log4j.appender.nodemanagerrequestlog.RetainDays=3
当然上述包含了所有配置信息,大多都被注释掉了~
三、开发Mapreduce程序需要引入哪些jar包(hadoop2.6为例说明)
虽然在eclipse软件中设置了hadoop的路径之后,再新建Mapreduce工程会自动将所需jar包导入,但如果是别人的mapreduce工程导入进mapreduce的话,就需要手动引入这些jar包,因此将需要引入的jar包做了整理,需手动导入以下目录的jar包,或者可以将这些jar提前保存为用户库,方便下次使用:
以下路径均不包含其子目录 %HADOOP_HOME%/share/hadoop/yarn/lib 下的所有jar包 %HADOOP_HOME%/share/hadoop/yarn/ 除包含test名称jar包的所有jar包 %HADOOP_HOME%/share/hadoop/hdfs/lib 下的所有jar包 %HADOOP_HOME%/share/hadoop/hdfs/ 除包含test名称jar包的所有jar包 %HADOOP_HOME%/share/hadoop/mapreduce/lib 下的所有jar包 %HADOOP_HOME%/share/hadoop/mapreduce/ 除包含test名称jar包的所有jar包 %HADOOP_HOME%/share/hadoop/common/lib 下的所有jar包 %HADOOP_HOME%/share/hadoop/common/ 除包含test名称jar包的所有jar包
3 条评论
分享的不错,谢谢
比较全唉 可以借鉴