Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
Mahout中实现决策树算法的有两个(quick start),分别是Partial Implementation和Breiman Example,可以点击链接到相应的网页查看其官方实例。其中Breiman Example是单机版的,而Partial Implementation是可以使用map-reduce模式的。
Partial Implementation可以分为三步:Describe、BuildForest、TestForest,共称为决策树三部曲。以前有写过相关的内容,今次重新写这个算法的分析,应该会有一些更加深入的认知。本篇介绍三部曲之一Describe。
Describe在mahout-examples-0.7-job.jar包中的\org\apache\mahout\classifier\df\tools 路径下,在myeclipse中打开此文件,可以看到该类的源码。直接运行该类(含有main函数,可以直接运行),可以看到该类的使用指南:
Usage:
[--path <path> --file <file> --descriptor <descriptor1> [<descriptor2> ...]
--regression --help]
Options
--path (-p) path Data path
--file (-f) file Path to generated descriptor
file
--descriptor (-d) descriptor [descriptor ...] data descriptor
--regression (-r) Regression Problem
--help (-h)该类主要的作用是把原始文件的描述写入一个文件。进入main函数,可以看到代码刚开始都是参数的传递,使用Option类来进行参数解析。然后就直接到了runTool()方法,这个是主要的操作,看到这个函数的参数有:dataPath(原始数据的输入路径),descriptor(对原始文件的描述,list),descPath(描述文件生成的路径),regression(是否是回归问题,由于这里做的是非回归问题,所以这个参数可以暂时忽略)。
采用的测试数据:glass.data,测试类:
package test.breiman;
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.mahout.classifier.df.data.DescriptorException;
import org.apache.mahout.classifier.df.tools.Describe;
import org.apache.mahout.common.HadoopUtil;
public class DescribeFollow {
/**
* @param 测试Describe
* @throws DescriptorException
* @throws IOException
*/
public static void main(String[] args) throws IOException, DescriptorException {
String[] arg=new String[]{"-p","hdfs://ubuntu:9000/user/breiman/input/glass.data",
"-f","hdfs://ubuntu:9000/user/breiman/glass.info2","-d","I","9","N","L"};
// System.out.println(arg[Arrays.asList(arg).indexOf("-f")+1]);
HadoopUtil.delete(new Configuration(), new Path(arg[Arrays.asList(arg).indexOf("-f")+1]));
Describe.main(arg);
}
}
首先简单介绍下输入数据:
1,1.52101,13.64,4.49,1.10,71.78,0.06,8.75,0.00,0.00,1 2,1.51761,13.89,3.60,1.36,72.73,0.48,7.83,0.00,0.00,1
<pre code_snippet_id="619404" snippet_file_name="blog_20150314_4_1861931" style="word-wrap:break-word; white-space:pre-wrap">71,1.51574,14.86,3.67,1.74,71.87,0.16,7.36,0.00,0.12,2 72,1.51848,13.64,3.87,1.27,71.96,0.54,8.32,0.00,0.32,2</pre>
每一个样本都有11个维度,第一维度是样本的编号(从1开始),最后一维是样本的标签。中间9个维度是样本的属性,都是数值型的。所以--descriptor参数设置为[I,9,N,L],I表示为忽视,是ignore的缩写,N是Numerical的缩写,L表示Label。当然如果维度中有非数值型的属性,也是可以的用C表示(Categorical的缩写)。9表示九个都是N,如果属性是这样的[Ignore,Numerical,Numerical,Categorical,Numerical,Categorical,Categorical,Label],那么--descriptor参数就应该写为下面的方式:[I,2,N,C,N,2,C,L]。
在runTool()里面的第一行设置断点,可以看到形参中的descriptor是:[I, 9, N, L]。在runTool中一共进行了四个操作:
String descriptor = DescriptorUtils.generateDescriptor(description); Path fPath = validateOutput(filePath); Dataset dataset = generateDataset(descriptor, dataPath, regression); DFUtils.storeWritable(new Configuration(), fPath, dataset);
其中的validateOutput应该可以忽略的(主要是判断输出文件是否存在而已,在DescribeFollow的时候不管输出文件是否存在都把它删除了,所以这里肯定是不存在问题的了)。那么generateDescriptor方法是做什么用的呢?就是一个转换,debug直接进行下一步,可以看到descriptor的值为:[I N N N N N N N N N L],就等于是把数字表示的全部转为字符了。generateDataset方法对应的是DataLoader.generateDataset(descriptor, regression, fs, path)这个方法,进入DataLoader类里面的这个方法。这个方法内主要进行了三个操作:
Attribute[] attrs = DescriptorUtils.parseDescriptor(descriptor);
if (parseString(attrs, valsets, line, regression)) {
size++;
}
List<String>[] values = new List[attrs.length];
for (int i = 0; i < valsets.length; i++) {
if (valsets[i] != null) {
values[i] = Lists.newArrayList(valsets[i]);
}
}第一步是把descriptor转换为全拼,如下:[IGNORED, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, NUMERICAL, LABEL];第二步采用parseString方法去遍历所有的输入文件,看输入文件是否满足descriptor的描述,是则把行数加1,即样本数加1(glass.data的数据,size为214,符合原始数据的样本数);第三步是把标识全部取出来放入values中,values中的值为:[null, null, null, null, null, null, null, null, null, null, [3, 2, 1, 7, 6, 5]]至于values中的最后一个表示标识的为什么不是[1,2,3,5,6,7],是因为在parseString方式中这里的set是HashSet,采用随机存放的方式。该方法返回:
return new Dataset(attrs, values, size, regression);
返回一个dataset,这个dataSet中有属性、标识、样本数。
debug方式下看到的dataset如下:
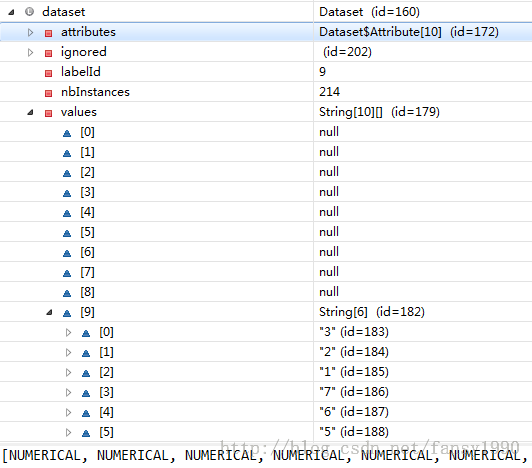
到最后一步,DFUtils.storeWritable(new Configuration(), fPath, dataset);直接把dataset写入了文件,看这个方法:
public static void storeWritable(Configuration conf, Path path, Writable writable) throws IOException
里面的最后一个形参是writable的,但是我们传入的是dataset,可以么?看dataset的定义就可以了,看到DataSet是实现了Writable接口的,所以,这个是没有问题的。
BuildForest是在mahout-examples-0.7-job.jar包的org\apache\mahout\classifier\df\mapreduce 路径下。直接运行该类,可以看到该类的使用方式:
Usage:
[--data <path> --dataset <dataset> --selection <m> --no-complete --minsplit
<minsplit> --minprop <minprop> --seed <seed> --partial --nbtrees <nbtrees>
--output <path> --help]
Options
--data (-d) path Data path
--dataset (-ds) dataset Dataset path
--selection (-sl) m Optional, Number of variables to select randomly
at each tree-node.
For classification problem, the default is
square root of the number of explanatory
variables.
For regression problem, the default is 1/3 of
the number of explanatory variables.
--no-complete (-nc) Optional, The tree is not complemented
--minsplit (-ms) minsplit Optional, The tree-node is not divided, if the
branching data size is smaller than this value.
The default is 2.
--minprop (-mp) minprop Optional, The tree-node is not divided, if the
proportion of the variance of branching data is
smaller than this value.
In the case of a regression problem, this value
is used. The default is 1/1000(0.001).
--seed (-sd) seed Optional, seed value used to initialise the
Random number generator
--partial (-p) Optional, use the Partial Data implementation
--nbtrees (-t) nbtrees Number of trees to grow
--output (-o) path Output path, will contain the Decision Forest
--help (-h) Print out help
这个类刚开始也是设置参数,然后直接进入到buildForest()方法中。这个方法主要包含下面的四个步骤:
DecisionTreeBuilder treeBuilder = new DecisionTreeBuilder();
Builder forestBuilder;
if (isPartial) {
forestBuilder = new PartialBuilder(treeBuilder, dataPath, datasetPath, seed, getConf());
}
DecisionForest forest = forestBuilder.build(nbTrees);
DFUtils.storeWritable(getConf(), forestPath, forest);1. 新建treeBuilder,设置每次随机选择属性的样本个数,默认是所有属性的1/3,设置complemented,默认是true的,其他的属性参数基本也是默认的,设置断点,可以看到该变量的值如下:
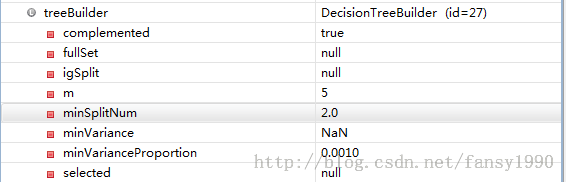
2. 新建PartialBuilder,设置相关的参数,得到下面的forestBuilder的值如下:
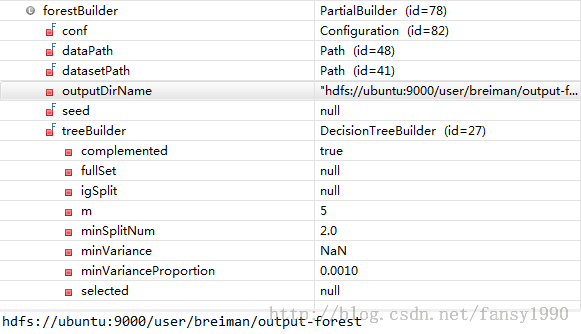
3.build方法,这个是重点了。
进入到Builder中的build方法中,看到是一些设置相关变量的代码:setRandomSeed、setNbTrees、setTreeBuilder。然后把dataset的路径加入到了distributedCache中,这样在Mapper中就可以直接读出这个路径了(相当于放在了内存中)。然后就是新建Job了,名字为decision forest builder,初始化这个Job,运行:
Job job = new Job(conf, "decision forest builder");
configureJob(job);
if (!runJob(job)) {
log.error("Job failed!");
return null;
}初始化:configureJob,看到Builder的子类PartialBuilder中的configureJob方法。
Configuration conf = job.getConfiguration();
job.setJarByClass(PartialBuilder.class);
FileInputFormat.setInputPaths(job, getDataPath());
FileOutputFormat.setOutputPath(job, getOutputPath(conf));
job.setOutputKeyClass(TreeID.class);
job.setOutputValueClass(MapredOutput.class);
job.setMapperClass(Step1Mapper.class);
job.setNumReduceTasks(0); // no reducers
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);可以看到都是一些基本的设置,设置输出的<key,value>的格式,设置Mapper为Step1Mapper,设置Reducer为空,设置输入、输出的路径格式(序列、字符串)。
那下面其实只用分析Step1Mapper就可以了。
分析Step1Mapper需要分析它的数据流,打开该类文件,看到该Mapper有setup、map、cleanup三个函数,且在cleanup函数中进行输出。首先看setup函数,这个函数如下:
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
Configuration conf = context.getConfiguration();
configure(Builder.getRandomSeed(conf), conf.getInt("mapred.task.partition", -1),
Builder.getNumMaps(conf), Builder.getNbTrees(conf));
}进入到configure中查看该函数源码:
protected void configure(Long seed, int partition, int numMapTasks, int numTrees) {
converter = new DataConverter(getDataset());
// prepare random-numders generator
log.debug("seed : {}", seed);
if (seed == null) {
rng = RandomUtils.getRandom();
} else {
rng = RandomUtils.getRandom(seed);
}
log.info("partition : {}",partition);
System.out.println(new Date()+"partition : "+partition);
// mapper's partition
Preconditions.checkArgument(partition >= 0, "Wrong partition ID");
this.partition = partition;
// compute number of trees to build
nbTrees = nbTrees(numMapTasks, numTrees, partition);
// compute first tree id
firstTreeId = 0;
for (int p = 0; p < partition; p++) {
firstTreeId += nbTrees(numMapTasks, numTrees, p);
}
System.out.println(new Date()+"partition : "+partition);
log.info("partition : {}", partition);
log.info("nbTrees : {}", nbTrees);
log.info("firstTreeId : {}", firstTreeId);
}因seed没有设置,所以传入的是null,那么这里的代码会自动进行赋值,然后到了partition这个变量,这个变量是由conf.getInt("mapred.task.partition", -1)这样得到的,但是在conf里面应该没有设置mapred.task.partition这个变量,所以这样得到的partition应该是-1,然后就到了Preconditions.checkArgument(partition>=0,"Wrong partition ID")这一行代码了,但是这里如果partition是-1的话,肯定会报错的吧,但是程序没有报错,所以可以认定这里的partition不是-1?
编写了BuildForest的仿制代码如下:
package mahout.fansy.partial;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.util.ToolRunner;
import org.apache.mahout.classifier.df.DecisionForest;
import org.apache.mahout.classifier.df.builder.DecisionTreeBuilder;
import org.apache.mahout.classifier.df.mapreduce.Builder;
import org.apache.mahout.classifier.df.mapreduce.partial.PartialBuilder;
import org.apache.mahout.common.AbstractJob;
public class BuildForestFollow extends AbstractJob {
private int m;
private int nbTrees;
private Path datasetPath;
private Path dataPath;
private Path outPath;
private boolean complemented=true;
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
addInputOption();
addOutputOption();
addOption("selection","sl", " Optional, Number of variables to select randomly at each tree-node."+
"For classification problem, the default is square root of the number of explanatory"+
"variables. For regression problem, the default is 1/3 of"+
"the number of explanatory variables");
addOption("nbtrees","t","Number of trees to grow ");
addOption("dataset","ds","Dataset path ");
if (parseArguments(args) == null) {
return -1;
}
dataPath = getInputPath();
outPath = getOutputPath();
datasetPath=new Path(getOption("dataset"));
m=Integer.parseInt(getOption("selection"));
nbTrees=Integer.parseInt(getOption("nbtrees"));
conf=getConf();
init();
return 0;
}
private void init() throws IOException, ClassNotFoundException, InterruptedException{
FileSystem ofs = outPath.getFileSystem(getConf());
if (ofs.exists(outputPath)) {
ofs.deleteOnExit(outPath);
}
DecisionTreeBuilder treeBuilder = new DecisionTreeBuilder();
treeBuilder.setM(m);
treeBuilder.setComplemented(complemented);
Builder forestBuilder=new PartialBuilder(treeBuilder, dataPath, datasetPath, null, conf);;
forestBuilder.setOutputDirName(outputPath.toString()); // 此处一定要设置为这样的方式,而非outputPath.getName(),
//否则后面会出现权限问题
DecisionForest forest = forestBuilder.build(nbTrees);
System.out.println(forest);
}
public static void main(String[] args) throws Exception{
ToolRunner.run(new Configuration(),new BuildForestFollow(), args);
}
}
编写测试代码如下:
package mahout.fansy.partial.test;
import com.google.common.base.Preconditions;
import mahout.fansy.partial.BuildForestFollow;
public class TestBuildForestFollow {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String[] arg=new String[]{"-jt","ubuntu:9001","-fs","ubuntu:9000",
"-i","hdfs://ubuntu:9000/user/breiman/input/glass.data",
"-ds","hdfs://ubuntu:9000/user/breiman/glass.info",
"-sl","5",
"-t","10",
"-o","hdfs://ubuntu:9000/user/breiman/output-forest"
};
BuildForestFollow.main(arg);
// int a=1;
// Preconditions.checkArgument(a >= 0, "Wrong partition ID");
}
}
上面的测试代码同样没有对conf设置mapred.task.partition变量,但是程序依然可以跑,没有报错。所以我就想在Step1Mapper中进行设置信息打印出来,
由于debug模式不会用,所以我就把log.debug全部改为了log.info,并替换了mahout-examples-0.7-job.jar文件中的相应class文件,但是依然没有打印出来相关的信息,郁闷。。。
然后我就修改了Builder类中的相应信息(在290行左右,修改完编译后同样替换mahout-examples-0.7-job.jar中对应的文件):
Job job = new Job(conf, "decision forest builder");
log.info("partition : {}",conf.getInt("mapred.task.partition", -1));
log.info("Configuring the job...");这样就可以在job提交之前,conf不会变的情况下进行partition的查看。运行前面的测试,得到:
13/09/21 23:53:10 INFO common.AbstractJob: Command line arguments: {--dataset=[hdfs://ubuntu:9000/user/breiman/glass.info], --endPhase=[2147483647], --input=[hdfs://ubuntu:9000/user/breiman/input/glass.data], --nbtrees=[10], --output=[hdfs://ubuntu:9000/user/breiman/output-forest], --selection=[5], --startPhase=[0], --tempDir=[temp]}
13/09/21 23:53:11 INFO mapreduce.Builder: partition : -1
13/09/21 23:53:11 INFO mapreduce.Builder: Configuring the job...
13/09/21 23:53:11 INFO mapreduce.Builder: Running the job...这里可以看到partition的确是-1,那么在setup函数中在执行conf.getInt("mapred.task.partition", -1)这一句之前哪里对conf进行了修改么?然后对mapred.task.parition进行了赋值?可能的解决方法还是应该去看Setp1Mapper 中的信息,在conf.getInt("mapred.task.partition", -1)之后,Preconditions.checkArgument(partition >= 0, "Wrong partition ID");之前查看partition的值,但是如何做呢?
昨天遇到的问题原来是找错包了,那个Step1Mapper.class 同时在mahout-core-0.7.jar mahout-core-0.7-job.jar mahout-examples-0.7-job.jar 三个包中,但是用到的只是mahout-core-0.7.jar中的Step1Mapper.class,所以只用替换mahout-core-0.7.jar中相应的文件即可。出来的结果如下:

可以看到这里的partition已经变成了0了,这个值是在哪里设置的?
Step1Mapper中log的设置如下:
protected void setup(Context context) throws IOException, InterruptedException {
log.info("in setup() before super.setup() partition : {}",
context.getConfiguration().getInt("mapred.task.partition", -1));
super.setup(context);
Configuration conf = context.getConfiguration();
log.info("in setup() after super.setup() partition : {}",
conf.getInt("mapred.task.partition", -1));
configure(Builder.getRandomSeed(conf), conf.getInt("mapred.task.partition", -1),
Builder.getNumMaps(conf), Builder.getNbTrees(conf));
}可以看到我在setup函数刚进来的时候还没有执行super.setup的时候mapred.task.partition就已经被赋值了,这点如何说明?
看PartialBuilder,我在PartialBuilder中加入了下面的语句:
protected void configureJob(Job job) throws IOException {
Configuration conf = job.getConfiguration();
log.info("in PartialBuilder configureJob() partition : {}",
conf.getInt("mapred.task.partition", -1));
job.setJarByClass(PartialBuilder.class);
FileInputFormat.setInputPaths(job, getDataPath());
FileOutputFormat.setOutputPath(job, getOutputPath(conf));
job.setOutputKeyClass(TreeID.class);
job.setOutputValueClass(MapredOutput.class);
job.setMapperClass(Step1Mapper.class);
job.setNumReduceTasks(0); // no reducers
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
}这里是设置Job的和conf的,我在conf不会变的情况下,读取了它的值,如下:

可以看到这个值还是没有设置的,如果设置的话不应该读到-1。
所以得到的结论就是Job提交之前conf没有设置mapred.task.partition的值,但是刚提交,在Mapper的第一个运行函数setup中就可以读取conf的mapred.task.partition的值了,这是神马情况?难道其他地方还有设置这个值的?好吧,我搜搜看:
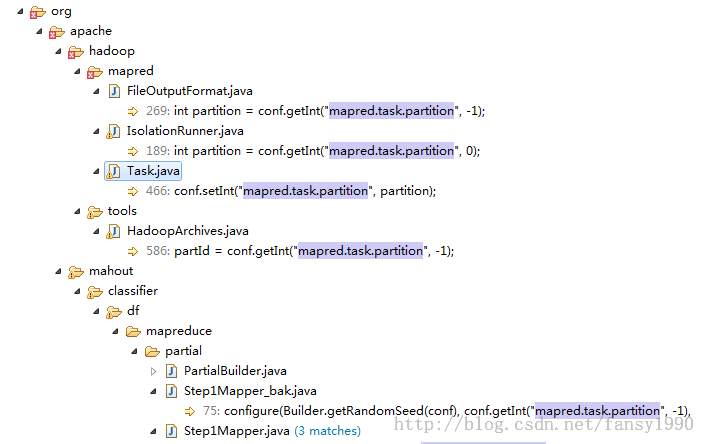
尼玛,还真有。除了mahou里面的,hadoop里面也有三个类含有这个值:FileOutputFormat、IsolationRunner、Task。这三个中只有Task最像是设置mapred.task.partition的值的类。Task:任务。好吧,应该就是这里设置了这个值了。好吧,我为啥老是追着这个值不放?因为我编写Step1Mapper 的仿制代码的时候需要这个值,而我又不知道这个值是多少,坑爹呀。昨天就应该知道的,结果替换错了.class文件了。算了,不纠结这个变量值了,知道了就好。如果真要追究的话,应该要涉及到hadoop的执行原理了吧。
今天到BuildForest的主要Mapper操作,前面也说到BuildForest主要的操作都在Mapper里面,而reducer是没有的。本篇介绍其Mapper,Step1Mapper。首先贴上其仿制代码,如下:
package mahout.fansy.partial;
import java.io.IOException;
import java.util.List;
import java.util.Random;
import mahout.fansy.utils.read.ReadText;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.mahout.classifier.df.Bagging;
import org.apache.mahout.classifier.df.builder.DecisionTreeBuilder;
import org.apache.mahout.classifier.df.data.Data;
import org.apache.mahout.classifier.df.data.DataConverter;
import org.apache.mahout.classifier.df.data.Dataset;
import org.apache.mahout.classifier.df.data.Instance;
import org.apache.mahout.classifier.df.mapreduce.Builder;
import org.apache.mahout.classifier.df.mapreduce.MapredOutput;
import org.apache.mahout.classifier.df.mapreduce.partial.TreeID;
import org.apache.mahout.classifier.df.node.Node;
import org.apache.mahout.common.RandomUtils;
import com.google.common.base.Preconditions;
import com.google.common.collect.Lists;
/**
* Step1Mapper的仿造代码
* @author fansy
*/
public class Step1MapperFollow {
private DataConverter converter;
private Random rng;
private int nbTrees;
private int firstTreeId;
private int partition;
private final List<Instance> instances = Lists.newArrayList();
private Configuration conf;
private Path datasetPath ;
private Path input;
// private Path output;
private List<Text> values;
private Dataset dataset;
private DecisionTreeBuilder treeBuilder;
private int m; // selection
public static void main(String[] args) throws IOException, InterruptedException{
Step1MapperFollow s1m=new Step1MapperFollow();
s1m.init();
s1m.setup();
s1m.map();
s1m.cleanup();
}
/*
* 运行该类时首先要先运行该函数
*/
private void init() throws IOException{
datasetPath=new Path("hdfs://ubuntu:9000/user/breiman/glass.info");
input=new Path("hdfs://ubuntu:9000/user/breiman/input/glass.data");
// output=new Path("hdfs://ubuntu:9000/user/breiman/output-forest");
treeBuilder = new DecisionTreeBuilder();
treeBuilder.setM(m);
treeBuilder.setComplemented(true);
conf=new Configuration();
conf.set("mapred.job.tracker", "ubuntu:9001");
// 把dataset加入内存中
DistributedCache.addCacheFile(datasetPath.toUri(), conf);
dataset=Dataset.load(conf,datasetPath);
values=getData();
}
private List<Text> getData() throws IOException {
return ReadText.readText(input, conf);
}
/*
* 仿造setup函数
*/
public void setup() throws IOException{
// configure(Builder.getRandomSeed(conf), conf.getInt("mapred.task.partition", -1),
// Builder.getNumMaps(conf), Builder.getNbTrees(conf));
// conf.getInt("mapred.task.partition", -1)的值直接设置为0即可
// 参数设置参考上面
configure(Builder.getRandomSeed(conf), 0,
1, 10);
}
/*
* 仿造map函数
*/
protected void map() throws IOException {
// List<Text> values =ReadText.readText(input, conf);
for(Text value:values){
String[] v=value.toString().split(",");
if(v[10].equals("2")){
// System.out.println(v[10]);
}
instances.add(converter.convert(value.toString()));
}
}
/*
* 仿造cleanup函数
*/
protected void cleanup() throws IOException, InterruptedException {
// prepare the data
Data data = new Data(dataset, instances);
Bagging bagging = new Bagging(treeBuilder, data);
TreeID key = new TreeID();
for (int treeId = 0; treeId < nbTrees; treeId++) {
Node tree = bagging.build(rng);
key.set(partition, firstTreeId + treeId);
// if (!isNoOutput()) {
MapredOutput emOut = new MapredOutput(tree);
System.out.println("key:"+key+"***value:"+emOut);
// context.write(key, emOut);
// }
}
}
protected void configure(Long seed, int partition, int numMapTasks, int numTrees) throws IOException {
converter = new DataConverter(dataset);
// prepare random-numders generator
if (seed == null) {
rng = RandomUtils.getRandom();
} else {
rng = RandomUtils.getRandom(seed);
}
// mapper's partition
Preconditions.checkArgument(partition >= 0, "Wrong partition ID");
this.partition = partition;
// compute number of trees to build
nbTrees = nbTrees(numMapTasks, numTrees, partition);
// compute first tree id
firstTreeId = 0;
for (int p = 0; p < partition; p++) {
firstTreeId += nbTrees(numMapTasks, numTrees, p);
}
}
public static int nbTrees(int numMaps, int numTrees, int partition) {
int nbTrees = numTrees / numMaps;
if (partition == 0) {
nbTrees += numTrees - nbTrees * numMaps;
}
return nbTrees;
}
}
(1)setup函数
这个函数其实应该包括init里面的所有东东,这里设定的主要包括;Random随机种子、nbTrees决策树的个数、dataset的路径、data的路径。把data读入到values集合里面、把dataset读到dataset变量,新建treeBuilder变量设定其相关属性值,新建converter变量。
(2)map函数
map函数就是遍历每行的输入,然后使用converter把读入的数据进行转换,然后添加到instances里面,首先看下instances变量吧。这个变量定义如下:List<Instance>,这个是一个list,然后看到Instance类,Instance类里面就一个属性Vector和若干方法,可以看到其实Instance里面就是存储的Vector而已,不清楚搞多个Instance干嘛,直接Vector不好么?接下来看DataConverter,它有两个属性,一个是Pattern的用于分解string字符串的,另外一个是dataset,用于convert方法中相关值的设定。还有一个比较重要的方法convert方法,这个是用于把字符串转换为Vector(准确来说是Instance)的函数。在讲这个函数前,先来看下dataset吧:

假如我传入的字符串是:[1,1.52101,13.64,4.49,1.10,71.78,0.06,8.75,0.00,0.00,1],那么convert函数首先使用逗号把字符串解析到数组中,然后根据ignored的值把数组中对应的下标的值忽略,再次根据attributes的值进行匹配,如果是Numerical的话直接把值加入vector中,如果是categorical的话就按照values里面的数组进行匹配,比如如果是字符串“3”的话,那么就把其下标值加入vector中,比如上面的数据是1,那么加入字符串中的值就是2。可以通过debug方式查看添加这行输入后vector的值:
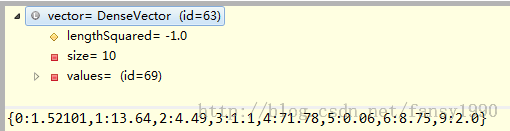
这里可以看到字符串1(这里一定要看做是字符串,而不是数字)的确是被转换为了2了,而且可以看到由于第7、8的值为0,所以这里就没有显示了。
(3)cleanup函数
看cleanup函数,刚开始新建了几个变量、Data、Bagging、TreeID,然后循环调用build函数建立树并输出每棵树,每棵树是由Node类带出的。所以这里的重点是build函数。
Bagging.build函数传入一个随机种子,然后返回一个Node,这个Node就是一个树了,这个Node可以往左、右继续添加Node。继续看这个函数的代码:
Arrays.fill(sampled, false);
Data bag = data.bagging(rng, sampled);
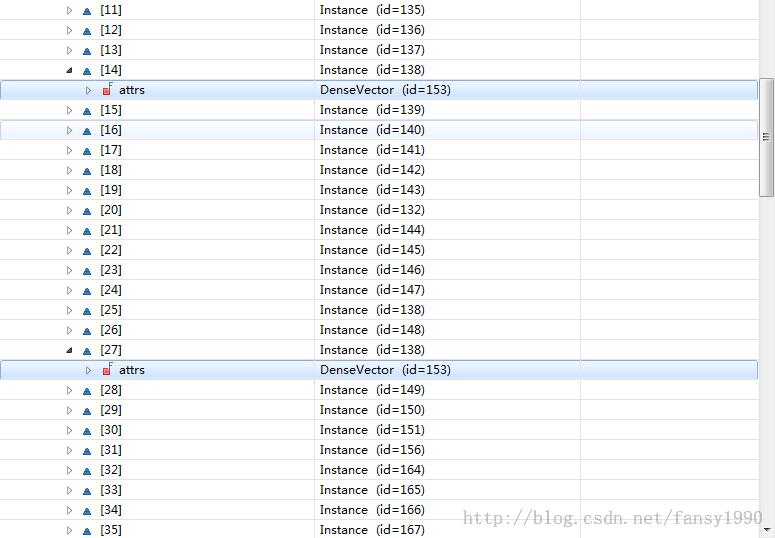
return treeBuilder.build(rng, bag);看到这里首先对Data进行了一个.bagging(rng)的处理,然后把处理后的data传入了treeBuilder的build函数。一个个来看data.bagging是做什么处理的呢?
public Data bagging(Random rng, boolean[] sampled) {
int datasize = size();
List<Instance> bag = Lists.newArrayListWithCapacity(datasize);
for (int i = 0; i < datasize; i++) {
int index = rng.nextInt(datasize);
bag.add(instances.get(index));
sampled[index] = true;
}
return new Data(dataset, bag);
}instaces是原始数据的list,可以看到bag每次添加了一个从instances中随机取出的一个vector值,然后进行返回,同时修改了sampled的值(这个值是说instances的哪个下标已经被选中了),所以返回的bag值里面肯定是有重复的,如下:
下面到了treeBuilder.build方法,这个方法被两个类覆写,分别是DecisionTreeBuilder、DefaultTreeBuilder,这里调用的是DecisionTreeBuilder的build方法。
刚开始是如下的代码:
if (selected == null) {
selected = new boolean[data.getDataset().nbAttributes()];
selected[data.getDataset().getLabelId()] = true; // never select the label
}
if (m == 0) {
// set default m
double e = data.getDataset().nbAttributes() - 1;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
// regression
m = (int) Math.ceil(e / 3.0);
} else {
// classification
m = (int) Math.ceil(Math.sqrt(e));
}
}设定label的selected的值为true,其他属性值的selected被设置为false。然后设定m的值,由于m的值,前面没有设定,而这里是做分类问题的,所以设定m的值为所有属性值个数的平方根。这个m值是为了下面随机选择的属性值的个数。
下面的代码通过判断data.getDataset().isNumerical(data.getDataset().getLabelId())这个boolean值来进行判断是用回归还是分类思路来处理。这里的label肯定不是数值型的,所以进入分类处理的代码:
首先是两个判断:
if (isIdentical(data)) {
return new Leaf(data.majorityLabel(rng));
}
if (data.identicalLabel()) {
return new Leaf(data.getDataset().getLabel(data.get(0)));
}第一个判断是判断data是否全部都是一样的,第二个判断是判断data是否是空的;这里传入的data虽然有重复,但是不全是一样的,而且肯定不是为空,所以继续往下走。
int[] attributes = randomAttributes(rng, selected, m);
这行代码的主要意思是随机选择m个属性返回到attributes,比如这次debug得到的结果是:[8,2,6];然后到了下面的if (attributes == null || attributes.length == 0)这里跳过,下面if (igSplit == null) 对分类问题,这个赋值为:igSplit = new OptIgSplit();
代码继续走:
Split best = null;
for (int attr : attributes) {
Split split = igSplit.computeSplit(data, attr);
if (best == null || best.getIg() < split.getIg()) {
best = split;
}
}首先看下Split这个类,有三个属性:int attr,double ig,double split;来看下computeSplit函数(OptIgSplitl里面的函数):
public Split computeSplit(Data data, int attr) {
if (data.getDataset().isNumerical(attr)) {
return numericalSplit(data, attr);
} else {
return categoricalSplit(data, attr);
}
}又要进入函数,看numericalSplit函数:
Split numericalSplit(Data data, int attr) {
double[] values = sortedValues(data, attr);
initCounts(data, values);
computeFrequencies(data, attr, values);
int size = data.size();
double hy = entropy(countAll, size);
double invDataSize = 1.0 / size;
int best = -1;
double bestIg = -1.0;
// try each possible split value
for (int index = 0; index < values.length; index++) {
double ig = hy;
// instance with attribute value < values[index]
size = DataUtils.sum(countLess);
ig -= size * invDataSize * entropy(countLess, size);
// instance with attribute value >= values[index]
size = DataUtils.sum(countAll);
ig -= size * invDataSize * entropy(countAll, size);
if (ig > bestIg) {
bestIg = ig;
best = index;
}
DataUtils.add(countLess, counts[index]);
DataUtils.dec(countAll, counts[index]);
}
if (best == -1) {
throw new IllegalStateException("no best split found !");
}
return new Split(attr, bestIg, values[best]);
}分析到OptIgSplitl类的computeSplit函数里面的numbericalSplit函数,看这个函数的输入参数data和attr,应该是针对data计算出一个和attr相关的值而已。往下看
double[] values = sortedValues(data, attr); ,这一句是干啥的?
private static double[] sortedValues(Data data, int attr) {
double[] values = data.values(attr);
Arrays.sort(values);
return values;
}sortedValues就是把data中第attr个属性的值全部取出来,然后排个序(attr从0开始)。比如这次debug得到的三个属性s[5,1,4],第5个属性的值全部排序后得到的值如下:
[0.0, 0.02, 0.03, 0.04, 0.05, 0.06, 0.08, 0.09, 0.11, 0.12, 0.13, 0.14, 0.15, 0.16, 0.18, 0.19, 0.23, 0.31, 0.32, 0.33, 0.35, 0.37, 0.38, 0.39, 0.44, 0.45, 0.47, 0.48, 0.49, 0.51, 0.52, 0.53, 0.54, 0.55, 0.56, 0.57, 0.58, 0.59, 0.6, 0.61, 0.62, 0.63, 0.64, 0.65, 0.66, 0.67, 0.68, 0.69, 0.72, 0.73, 0.76, 0.81, 0.97, 1.1, 1.46, 1.68, 1.76, 2.7, 6.21]
这里一共有59个值,为什么只有在data.values()函数中把相同的值都去除了,采用的HashSet存储的,这个可以在Data类的第193行看到。
然后到了initCounts(data, values);这个就是初始化三个数组的函数,具体代码如下:
void initCounts(Data data, double[] values) {
counts = new int[values.length][data.getDataset().nblabels()];
countAll = new int[data.getDataset().nblabels()];
countLess = new int[data.getDataset().nblabels()];
}这里values.length就是59,data.getDataset().nblabels()就是6;
然后到了computeFrequencies(data, attr, values);这个函数主要计算了两个数组:counts[i][j],其中i表示0-58之间的一个数字,j表示0-5之间的一个数字。因为前面的214个数据删除了重复的才变为了59个,所以原始数据里面肯定是有重复的,这里就是计算这些重复的且它的label值要是一样的,比如原始数据如下(只写一列,因为这里只取了一列):
0.3 0
0.3 0
0.3 1
0.4 1
0.5 2
那么values=[0.3,0.4,0.5],counts[0][0]=2,counts[0][1]=1,counts[1][1]=1,counts[2][2]=1,其他counts的值都为0;countAll就是label的值分别相加,countAll[0]=2,countAll[1]=2,countAll[2]=1;
void computeFrequencies(Data data, int attr, double[] values) {
Dataset dataset = data.getDataset();
for (int index = 0; index < data.size(); index++) {
Instance instance = data.get(index);
counts[ArrayUtils.indexOf(values, instance.get(attr))][(int) dataset.getLabel(instance)]++;
countAll[(int) dataset.getLabel(instance)]++;
}
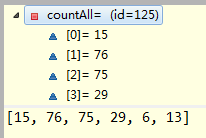
}比如上面的glass.data数据在attr是5的情况下得到的counts(size为59)和countAll(size为6)如下:
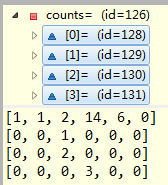

继续往下:int size = data.size(); double hy = entropy(countAll, size);这里的size就是214,entropy是啥来的?
private static double entropy(int[] counts, int dataSize) {
if (dataSize == 0) {
return 0.0;
}
double entropy = 0.0;
double invDataSize = 1.0 / dataSize;
for (int count : counts) {
if (count == 0) {
continue; // otherwise we get a NaN
}
double p = count * invDataSize;
entropy += -p * Math.log(p) / LOG2;
}
return entropy;
}这个好像叫做熵的?看下它是如何计算的:
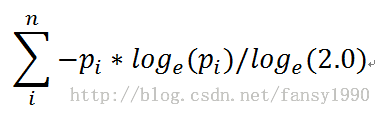
下面的公式中pi是每个label的重复值除以总数214的结果。
在继续往下面看:
double invDataSize = 1.0 / size;
int best = -1;
double bestIg = -1.0;
// try each possible split value
for (int index = 0; index < values.length; index++) {
double ig = hy;
// instance with attribute value < values[index]
size = DataUtils.sum(countLess);
ig -= size * invDataSize * entropy(countLess, size);
// instance with attribute value >= values[index]
size = DataUtils.sum(countAll);
ig -= size * invDataSize * entropy(countAll, size);
if (ig > bestIg) {
bestIg = ig;
best = index;
}
DataUtils.add(countLess, counts[index]);
DataUtils.dec(countAll, counts[index]);
}上面算到的hy是2.110138986672679。进入for循环,size = DataUtils.sum(countLess);由于第一次countLess全部值为0,所以size也为0,ig=ig-0;然后size = DataUtils.sum(countAll);这个size值为214;然后就是ig -= size * invDataSize * entropy(countAll, size); size*invDataSize不是1么,entropy(countAll,size)不就是hy么?ig前面不是把hy的值赋给它了么?所以ig=ig-hy=ig-ig=0?然后debug得出的答案是:4.440892098500626E-16。尼玛 ,还10的负十六次方。
然后是最后两行,这个是什么意思?运行前:
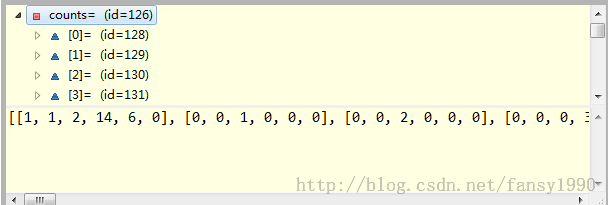
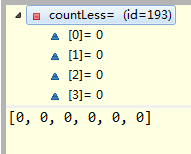
运行最后两行代码后,变为:
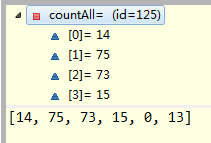
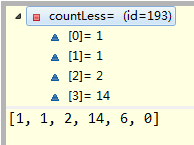
这样就不用我多说了吧,等于是把counts里面的第一条记录加到countLess中,然后再把countAll中相应的次数减去第一条记录。
下面的就是按照这种规律循环遍历最后得到一个 attr --> bestIg 、bestIndex 的对应关系,然后输出 return new Split(attr, bestIg, values[best]);
今晚就到这里吧,不要熬夜。。。
先来说说上篇最后的bestIg和bestIndex的求法。在说这个前,要首先明确一个数组的熵的求法,按照mahout中的源码针对这样的一个数组a=[1,3,7,3,0,2]其熵为:
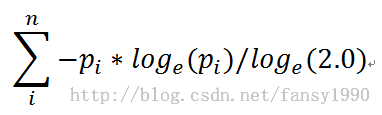
设sum=1+3+7+3+0+2,则其中pi对应于1/sum、3/sum、7/sum、3/sum、2/sum(其中若数组中的元素为0,则不参与计算),这个是数组熵的计算。
假如我有这样的一个数组counts:
[1,3,5,3,0] [0,9,2,4,2] [7,2,1,3,4] [4,3,6,8,3] [3,2,1,4,5]
那么首先我把对应的数字相加得到countAll=[15,19,15,22,14],然后求得countAll的熵hy,作为一个常数。然后把counts数组分为两部分前面i行和后面的5-i行分别为一组,然后求得这两组的熵分别是ig(i)、ig'(i),这两组对应的size(i)=所有元素相加值,size'(i)也等于所有元素相加值。比如size(1)=12。Size=counts所有元素相加,是一个常数。然后得到这样的一个常数Ig(i)=hy-size(i)*ig(i)/Size-size'(i)*ig'(i)/Size。i从0到4,这样就得到了5个Ig。最后bestIg=max(Ig(i)),bestIndex=bestIg对应的i值。
然后到返回值了return new Split(attr, bestIg, values[best]);这个Split有三个值,attr对应是属性的标识,bestIg是属性的衡量值,用于和其他属性做对比,values[best]是属性attr的分水岭,用于attr属性内部的比较。
代码继续往下看:
Split best = null;
for (int attr : attributes) {
Split split = igSplit.computeSplit(data, attr);
if (best == null || best.getIg() < split.getIg()) {
best = split;
}
}上面随机选择了三个属性,然后这里则取出其Ig值比较高的那个属性的Split。
代码继续:
Node childNode;
if (data.getDataset().isNumerical(best.getAttr())) {
boolean[] temp = null;
Data loSubset = data.subset(Condition.lesser(best.getAttr(), best.getSplit()));
Data hiSubset = data.subset(Condition.greaterOrEquals(best.getAttr(), best.getSplit()));
if (loSubset.isEmpty() || hiSubset.isEmpty()) {
// the selected attribute did not change the data, avoid using it in the child notes
selected[best.getAttr()] = true;
} else {
// the data changed, so we can unselect all previousely selected NUMERICAL attributes
temp = selected;
selected = cloneCategoricalAttributes(data.getDataset(), selected);
}
// size of the subset is less than the minSpitNum
if (loSubset.size() < minSplitNum || hiSubset.size() < minSplitNum) {
// branch is not split
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("branch is not split Leaf({})", label);
return new Leaf(label);
}
Node loChild = build(rng, loSubset);
Node hiChild = build(rng, hiSubset);
// restore the selection state of the attributes
if (temp != null) {
selected = temp;
} else {
selected[best.getAttr()] = alreadySelected;
}
childNode = new NumericalNode(best.getAttr(), best.getSplit(), loChild, hiChild);
}比如这次debug随机选择的三个属性是[4,2,0],然后计算得到属性2的Ig最大,所以首先选择属性2,属性2是Numerical的,所以直接进入到if下面的代码块
刚开始 Data loSubset = data.subset(Condition.lesser(best.getAttr(), best.getSplit())); Data hiSubset = data.subset(Condition.greaterOrEquals(best.getAttr(), best.getSplit()));这两句就是把所有数据按照属性bestAttr中的bestSplit来进行分组。若属性bestAttr中的值小于bestSplit的值,那么这条数据就被分给loSubset中,否则分给hiSubset中。debug模式查看这两个变量的值:
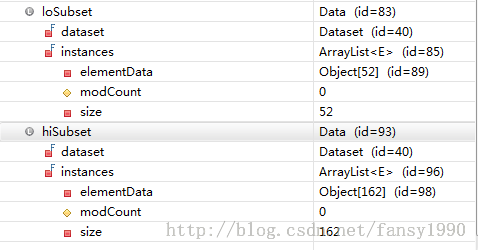
可以看到52+162=214,这说明这两个数组的确是由214条记录分离得到的。且分别观察loSubset、hiSubset,可以看到里面属性attr的值都是分别<bestSplit和>=bestSplit的。
下面到了Node loChild = build(rng, loSubset);然后又到了build函数,这次data是含有52条记录的数据了。然后又随机取出三个属性,计算得到最优的属性,然后再按照最优的属性把数据分为两部分,然后再build()。啥时候退出循环呢?
if (loSubset.size() < minSplitNum || hiSubset.size() < minSplitNum) {
// branch is not split
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("branch is not split Leaf({})", label);
return new Leaf(label);
}这里可以看到当分组后的两部分数据中的其中一部分数据小于给定的阈值minSplitNum(终于知道这个值是用来干啥的了)的时候,就退出循环。返回的new Leaf(label)中的label是哪个label呢?是data中label最多的那个,可以参见下面的代码:
public int majorityLabel(Random rng) {
// count the frequency of each label value
int[] counts = new int[dataset.nblabels()];
for (int index = 0; index < size(); index++) {
counts[(int) dataset.getLabel(get(index))]++;
}
// find the label values that appears the most
return DataUtils.maxindex(rng, counts);
}最后返回的childNode是什么? childNode = new NumericalNode(best.getAttr(), best.getSplit(), loChild, hiChild);可以看到这个childNode包含四个属性,第一个是属性attr,第二个是该属性的分水岭bestSplit,第三个是左子树,第四个是右子树。
通过上面不断的递归循环,最后得到一棵树,调用返回到Step1MapperFollow的 Node tree=bagging.build(rng)上面来。比如某次debug的树如下:

对应的树画出来如下所示:
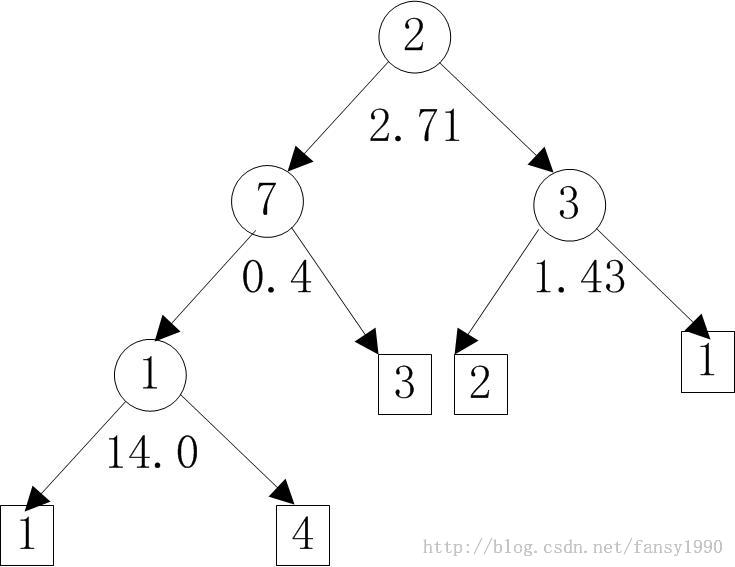
左边是属性值小于中间的那个数字的,右边是大于或等于的。
然后就是设置下输出的格式key.set(partition, firstTreeId + treeId);
// if (!isNoOutput()) {
MapredOutput emOut = new MapredOutput(tree);
然后直接输出了,比如Step1MapperFollow的输出如下:
key:0***value:{NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,LEAF:;;;;;;,LEAF:;; | null}
key:1***value:{NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:NUMERICAL:LEAF:;,NUMERICAL:LEAF:;,LEAF:;;;,LEAF:;;;,LEAF:;;; | null}
key:2***value:{NUMERICAL:NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,LEAF:;;,NUMERICAL:LEAF:;,LEAF:;;; | null}
这样表示输出3棵树,其中最后一棵树就是上图的那棵树的打印字符串。这样Step1Mapper的仿制代码就分析完了,其实就是Step1Mapper的工作流分析完了。
首先贴上调用TestForest的代码(win7下面myeclipse调用TestForest,这里要设置Configuration,所以不能直接TestForest.main()来调用):
package mahout.fansy.partial.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.mahout.classifier.df.mapreduce.TestForest;
public class TestTestForest {
/**
* 测试TestForest
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String[] arg=new String[]{"-i","hdfs://ubuntu:9000/user/breiman/input/glass.data",
"-ds","hdfs://ubuntu:9000/user/breiman/glass.info",
"-m","hdfs://ubuntu:9000/user/breiman/glass.tree/forest.seq",
"-a","-mr",
"-o","hdfs://ubuntu:9000/user/breiman/out-testforest0"};
Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "ubuntu:9001");
// conf.set("fs.default.name", "hdfs://");
conf.set("fs.default.name", "ubuntu:9000");
TestForest tf=new TestForest();
tf.setConf(conf);
Configuration confq=tf.getConf();
System.out.println(confq);
tf.run(arg);
}
}
跑出来的结果如下:
13/09/25 00:14:51 INFO common.HadoopUtil: Deleting hdfs://ubuntu:9000/user/breiman/out-testforest0/mappers 13/09/25 00:14:51 INFO mapreduce.TestForest: ======================================================= Summary ------------------------------------------------------- Correctly Classified Instances : 208 97.1963% Incorrectly Classified Instances : 6 2.8037% Total Classified Instances : 214 ======================================================= Confusion Matrix ------------------------------------------------------- a b c d e f <--Classified as 15 0 2 0 0 0 | 17 a = 3 0 76 0 0 0 0 | 76 b = 2 0 2 68 0 0 0 | 70 c = 1 0 0 1 28 0 0 | 29 d = 7 0 0 0 0 9 0 | 9 e = 6 0 0 0 1 0 12 | 13 f = 5
可以看到mahout源码在Job任务运行完成后,直接把mapper的输出删去了,然后存入了一个文件(这个在源码中可以看出)。然后就是正确率了,可以看到正确率达到了97%,还行吧,毕竟是对原始数据的分类,这么高也是正常的。这个就不像上次分析的贝叶斯了,贝叶斯算法还有自动把数据分为两个部分的功能(一个训练,一个测试),这个算法没有。
下面看代码吧:
进入TestForest的run方法中,刚开始都是一些基本参数的设置。主要有:输入、输出(这个是最基本的了)、dataset路径、model路径(BuildForest的路径)、是否显示分析结果(就是上面的Summary部分)、是否采用mapreduce模式运行。
然后就进入testForest()方法了。进去后首先检查下output是否符合要求(就是是否存在,存在则抛出异常)。接着是model路径的判断,不存在抛出异常。最后才判断输入数据是否存在(汗,不是应该先判读输入数据是否存在的么?不过好像这三个都是要判断的,所以那个先那个后没关系吧)。
接着(本来我是打然后的,突然发现前面已经有然后了,所以就回退,打了个接着,汗,我居然把这句打出来了,好吧,好像又打多了)就是mapreduce()函数了。
这里先不说分析的内容,暂时只说Job的事情,Job的调用只有两句:
Classifier classifier = new Classifier(modelPath, dataPath, datasetPath, outputPath, getConf());
classifier.run();一句新建Classifier,一句run方法。新建对象基本可以忽略了,看run方法:
DistributedCache.addCacheFile(datasetPath.toUri(), conf);
log.info("Adding the decision forest to the DistributedCache");
DistributedCache.addCacheFile(forestPath.toUri(), conf);
Job job = new Job(conf, "decision forest classifier");
log.info("Configuring the job...");
configureJob(job);
log.info("Running the job...");
if (!job.waitForCompletion(true)) {
throw new IllegalStateException("Job failed!");
}先分别把dataset和model的路径加入到内存中,方便Job的Mapper调用,然后configureJob,然后直接就跑job了job.waitForCompletion(true);。这里看下configureJob的内容:
job.setJarByClass(Classifier.class);
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, mappersOutputPath);
job.setOutputKeyClass(DoubleWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(CMapper.class);
job.setNumReduceTasks(0); // no reducers
job.setInputFormatClass(CTextInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);看到基本是一些常规的设置,然后Mapper就是CMapper了,Reducer没有。看CMapper是怎么操作的:
setup函数主要代码就三行:
dataset = Dataset.load(conf, new Path(files[0].getPath()));
converter = new DataConverter(dataset);
forest = DecisionForest.load(conf, new Path(files[1].getPath()));分别设置dataset、converter、forest,其实就是从路径中把文件读出来而已。
map函数:
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (first) {
FileSplit split = (FileSplit) context.getInputSplit();
Path path = split.getPath(); // current split path
lvalue.set(path.getName());
lkey.set(key.get());
context.write(lkey, lvalue);
first = false;
}
String line = value.toString();
if (!line.isEmpty()) {
Instance instance = converter.convert(line);
double prediction = forest.classify(dataset, rng, instance);
lkey.set(dataset.getLabel(instance));
lvalue.set(Double.toString(prediction));
context.write(lkey, lvalue);
}
}首先if里面的判断不知道是干啥的,这个应该要去看下输出文件才行(输出文件被源码删除了,但是这个不难搞到,只要在删除前设置断点即可。这个应该要下次分析了)。
然后判断输入是否为空,否则由converter把输入的一行转换为Instance变量,然后由setup函数中读出来的forest去分析这个Instance,看它应该是属于哪一类的,然后把key就设置为instance原来的分类,value设置为forest的分类结果(这里不明白干嘛还要把double转换为String,直接输入DoubleWritable的类型不就行了?可能是方便analyzer的分析吧)。这里最重要的操作其实就是forest.classify函数了:
这里先简要说下,下次再详细分析吧。前面得到的forest不是有很多棵树的嘛(这个可以自己设定的),然后每棵树都可以对这个Instance进行分析得到一个分类结果,然后取这些分类结果重复次数最多的那个即可。好了,眼睛要罢工了。。。
关于分类不带标签的数据,可以参考: http://blog.csdn.net/fansy1990/article/details/49593737。
Mahout系列之Decision Forest写了几篇,其中的一些过程并没有详细说明,这里就分析一下,作为Decision Forest算法系列的结束篇。
主要的问题包括:(1)在Build Forest中分析完了Step1Mapper后就没有向下分析了,而是直接进行TestForest的分析了,中间其实还是有很多操作的,比如:把Step1Mapper的Job的输出进行转换写入文件。(2)在BuildForest中没有分析当输入是Categorical的情况,这种情况下面执行的某些步骤是不一样的,主要是在DecisionTreeBuilder中的build方法中的区分。(3)在前一篇中最后的使用forest进行对数据的分类只是简要的说了下,这里详细分析下代码。(4)决策树同样可以做回归分析,在Describe阶段设置为回归问题就可以了,但是这里就不想做分析了。下面来分条进行分析:
(1)在BuildForest中提交任务后实际运行的类是Builder中的build方法中的代码。这里面的代码任务运行后的代码如下:
if (isOutput(conf)) {
log.debug("Parsing the output...");
DecisionForest forest = parseOutput(job);
HadoopUtil.delete(conf, outputPath);
return forest;
}isOutput():
protected static boolean isOutput(Configuration conf) {
return conf.getBoolean("debug.mahout.rf.output", true);
}可以看到这个函数去判断是否设置了debug.mahout.rf.output,如果没有设置则返回true,否则,就说明设置过了就按照设置的值来返回。这里一般都没有设置,所以就会运行if里面的代码先把job的输出传入到forest变量,然后删除job的输出。看parseOutput的操作:
protected DecisionForest parseOutput(Job job) throws IOException {
Configuration conf = job.getConfiguration();
int numTrees = Builder.getNbTrees(conf);
Path outputPath = getOutputPath(conf);
TreeID[] keys = new TreeID[numTrees];
Node[] trees = new Node[numTrees];
processOutput(job, outputPath, keys, trees);
return new DecisionForest(Arrays.asList(trees));
}这里面又有一个processOutput函数,前面就是设置一些变量的size之类的,然后到processOutput函数,看这个函数:
protected static void processOutput(JobContext job,
Path outputPath,
TreeID[] keys,
Node[] trees) throws IOException {
Preconditions.checkArgument(keys == null && trees == null || keys != null && trees != null,
"if keys is null, trees should also be null");
Preconditions.checkArgument(keys == null || keys.length == trees.length, "keys.length != trees.length");
Configuration conf = job.getConfiguration();
FileSystem fs = outputPath.getFileSystem(conf);
Path[] outfiles = DFUtils.listOutputFiles(fs, outputPath);
// read all the outputs
int index = 0;
for (Path path : outfiles) {
for (Pair<TreeID,MapredOutput> record : new SequenceFileIterable<TreeID, MapredOutput>(path, conf)) {
TreeID key = record.getFirst();
MapredOutput value = record.getSecond();
if (keys != null) {
keys[index] = key;
}
if (trees != null) {
trees[index] = value.getTree();
}
index++;
}
}
// make sure we got all the keys/values
if (keys != null && index != keys.length) {
throw new IllegalStateException("Some key/values are missing from the output");
}
}这里看到就是把job的输出按条读出然后写入到Node[] trees数组中,然后把数组转换为list,赋值给DecisionForest变量new DecisionForest(Arrays.asList(trees))。最后返回到BuildForest中DFUtils.storeWritable(getConf(), forestPath, forest);,这个主要是写文件,基本没啥内容了。
(2)当输入数据中存在有Categorical的属性列时,最先的不同就是在dataset的values属性。这个values数组当输入数据属性是Numerical的时候对应的值就是null,如果是Categorical的时候就会存入相应的离散值。其次就是在DecisionTreeBuilder中find the best split这一部分的代码(源文件中192行),这里计算Split的时候分为了Categorical和Numerical,如下:
public Split computeSplit(Data data, int attr) {
if (data.getDataset().isNumerical(attr)) {
return numericalSplit(data, attr);
} else {
return categoricalSplit(data, attr);
}
}看categoricalSplit函数:
private static Split categoricalSplit(Data data, int attr) {
double[] values = data.values(attr);
int[][] counts = new int[values.length][data.getDataset().nblabels()];
int[] countAll = new int[data.getDataset().nblabels()];
Dataset dataset = data.getDataset();
// compute frequencies
for (int index = 0; index < data.size(); index++) {
Instance instance = data.get(index);
counts[ArrayUtils.indexOf(values, instance.get(attr))][(int) dataset.getLabel(instance)]++;
countAll[(int) dataset.getLabel(instance)]++;
}
int size = data.size();
double hy = entropy(countAll, size); // H(Y)
double hyx = 0.0; // H(Y|X)
double invDataSize = 1.0 / size;
for (int index = 0; index < values.length; index++) {
size = DataUtils.sum(counts[index]);
hyx += size * invDataSize * entropy(counts[index], size);
}
double ig = hy - hyx;
return new Split(attr, ig);
}这里返回的Split只有两个属性,其实因为属性值是离散的,所以这里只用确定是这个值或者不是即可,不会还要说比较值的大小(而且也没法比)。
然后就是建立节点的部分了。获得最佳属性后,根据这个属性是否是Numerical而进入不同的代码块,如果是Categorical的话,进入:
else { // CATEGORICAL attribute
double[] values = data.values(best.getAttr());
// tree is complemented
Collection<Double> subsetValues = null;
if (complemented) {
subsetValues = Sets.newHashSet();
for (double value : values) {
subsetValues.add(value);
}
values = fullSet.values(best.getAttr());
}
int cnt = 0;
Data[] subsets = new Data[values.length];
for (int index = 0; index < values.length; index++) {
if (complemented && !subsetValues.contains(values[index])) {
continue;
}
subsets[index] = data.subset(Condition.equals(best.getAttr(), values[index]));
if (subsets[index].size() >= minSplitNum) {
cnt++;
}
}
// size of the subset is less than the minSpitNum
if (cnt < 2) {
// branch is not split
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("branch is not split Leaf({})", label);
return new Leaf(label);
}
selected[best.getAttr()] = true;
Node[] children = new Node[values.length];
for (int index = 0; index < values.length; index++) {
if (complemented && (subsetValues == null || !subsetValues.contains(values[index]))) {
// tree is complemented
double label;
if (data.getDataset().isNumerical(data.getDataset().getLabelId())) {
label = sum / data.size();
} else {
label = data.majorityLabel(rng);
}
log.debug("complemented Leaf({})", label);
children[index] = new Leaf(label);
continue;
}
children[index] = build(rng, subsets[index]);
}
selected[best.getAttr()] = alreadySelected;
childNode = new CategoricalNode(best.getAttr(), values, children);
}其实上面的代码和Numerical差不多,可以说作为Numerical的一种特殊情况,即对于Numerical把其区分为等于属性值和不等于属性值即可(但是Numerical是分为小于和等于、大于两种)。其他基本就差不多了。
(3)用forest对数据Instance变量进行分类的代码是在DecisionForest的classify函数里面:
public double classify(Dataset dataset, Random rng, Instance instance) {
if (dataset.isNumerical(dataset.getLabelId())) {
double sum = 0;
int cnt = 0;
for (Node tree : trees) {
double prediction = tree.classify(instance);
if (prediction != -1) {
sum += prediction;
cnt++;
}
}
return sum / cnt;
} else {
int[] predictions = new int[dataset.nblabels()];
for (Node tree : trees) {
double prediction = tree.classify(instance);
if (prediction != -1) {
predictions[(int) prediction]++;
}
}
if (DataUtils.sum(predictions) == 0) {
return -1; // no prediction available
}上面就是前篇讲到的所有树都对这个数据进行分类,然后按最多次数的那个类别即是最后的结果。但是一棵树是如何分类的?这个又分为了两种,好吧,应该不难猜,就是Numerical的树和Categorical的树。分别来看,首先是Numerical:
public double classify(Instance instance) {
if (instance.get(attr) < split) {
return loChild.classify(instance);
} else {
return hiChild.classify(instance);
}
}看到它是去找它的子树去了,然后最后到哪里?其实是到了Leaf的classify函数了:
@Override
public double classify(Instance instance) {
return label;
}这个也是一个递归的过程,其实就是建树过程的一个反过程而已,这样其实Categorical也是一样的了,只是要做些转换而已:
public double classify(Instance instance) {
int index = ArrayUtils.indexOf(values, instance.get(attr));
if (index == -1) {
// value not available, we cannot predict
return -1;
}
return childs[index].classify(instance);
}这样基本就ok了,下次再看这个算法的时候应该是要分析回归问题了?
3 条评论
卧槽,好高端!
………………………………项目所需。。虽然并不是很懂。
您好,博主,想问下,在生成随机森林的过程中,有没有进行 oob error的估计呢?在源码中了找了很长时间,都没找到。